The Local AI Shift: Why Edge Inferencing Wins in 2026
Running large language models on personal hardware used to require a data center grade rack. Today, the landscape has changed. Small Language Models, or SLMs, now rival the reasoning capabilities of yesterday's giants while fitting comfortably inside 8GB of VRAM. Developers are moving away from centralized APIs for three main reasons: latency, cost, and absolute data sovereignty. When you host a model locally, your proprietary code and sensitive client data never leave your machine.
Performance benchmarks for 2026 show that 3B and 4B models are no longer toys. These compact architectures benefit from advanced distillation techniques and high-quality synthetic training data. According to a March 2026 report from LocalAI Master, a hybrid routing strategy that sends 95% of queries to local SLMs can reduce operational costs by over 90% compared to cloud-only deployments. Speed is another factor. Local models provide near-instant token generation, which is essential for real-time applications like terminal assistants or IDE integrations.

Selection Criteria: Throughput, VRAM, and Quantization
Choosing a model for local use requires balancing intelligence against hardware constraints. Most developers look at the parameter count first, but memory bandwidth and quantization levels are equally important. A 4-bit quantized model often retains 99% of its original intelligence while requiring half the memory. If you are working on a machine with a mobile GPU, every gigabyte of VRAM matters. You must also consider the context window. Processing long documents requires a model that can handle at least 32K tokens without losing coherence.
Latency is measured in tokens per second. For a smooth experience, you generally want at least 20 to 30 tokens per second. Many of the models released in 2025 and 2026 are optimized specifically for consumer GPUs like the NVIDIA RTX 50-series or Apple's M-series chips. These chips use dedicated tensor cores to accelerate the matrix multiplications at the heart of the transformer architecture. Selecting the right model involves a simple decision tree based on your primary task and available memory.
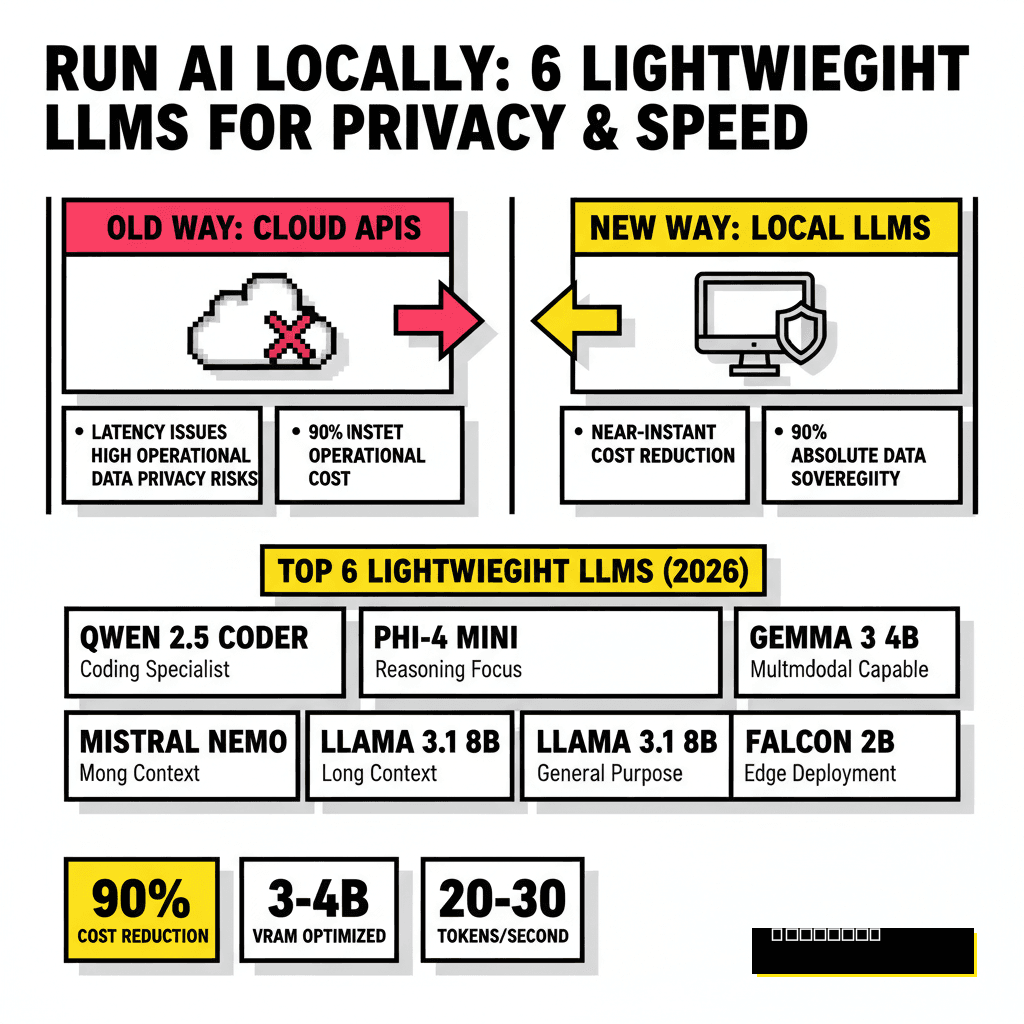
The Top 6 Lightweight Models for Your Local Rig
The 4B class of models has become the sweet spot for local deployment. These models are small enough to run on a standard laptop but powerful enough to handle complex instruction following. Below are the six best models currently available for local execution, ranging from reasoning specialists to coding powerhouses.
| Model Name | Size | Best Use Case | Context Window |
|---|---|---|---|
| Phi-4 Mini | 3.8B | Logical Reasoning | 128K |
| Nemotron-3-Nano | 4B | Finance & Logic | 32K |
| Gemma 3 4B | 4B | Multimodal Tasks | 128K |
| Qwen 2.5 Coder | 7B | Software Engineering | 128K |
| Mistral NeMo | 12B | Multilingual/Long Docs | 128K |
| DeepSeek-V3-Lite | MoE (Quant) | High-Efficiency Chat | 128K |
Phi-4 Mini stands out as Microsoft's reasoning powerhouse. It achieves an 84.8% MMLU score, which is remarkable for a model under 4 billion parameters. If you are building a tool that requires complex chain-of-thought logic, this is the top pick. NVIDIA's Nemotron-3-Nano, released in early 2026, has shown exceptional performance in financial reasoning and symbolic logic. It includes specific optimizations for the NVIDIA NIM ecosystem, making it a natural choice for Windows users with RTX hardware.
Gemma 3 4B is Google's contribution to the open weights community. This model is natively multimodal, meaning it can process images and text simultaneously on your local machine. Developers who need to automate visual document processing without sending images to the cloud will find this model invaluable. For those focusing on code, Qwen 2.5 Coder remains the gold standard. It hits 88.4% on the HumanEval benchmark, outperforming many proprietary models that are ten times its size. You can find more about deploying similar architectures in our guide on 6 No-Code Tools to Deploy Your Own Private Llama-4 Instance Locally.
Hardware Realities: PC vs. Mac for Local Inferencing
Hardware choice determines your maximum token throughput. PCs with dedicated NVIDIA GPUs offer the best raw performance thanks to CUDA cores and high-speed GDDR6X VRAM. An RTX 5080 or 5090 can run almost any model in the 7B to 12B range at full speed. However, Apple Silicon has a unique advantage in unified memory. Because the GPU and CPU share the same pool of RAM, a MacBook Pro with 128GB of memory can run much larger models than a PC with a 24GB graphics card, albeit at slightly lower speeds.
VRAM capacity is the strict limit for local models. If a model does not fit in your GPU memory, it will offload to system RAM, causing performance to drop by 90% or more. Many users solve this by using GGUF or EXL2 quantization formats. These formats allow you to squeeze a 12B model into 8GB or 12GB of memory. Choosing between these platforms depends on whether you prioritize raw speed or the ability to run larger, more complex models on a single device.
NVIDIA RTX Setup
- Highest tokens per second (TPS)
- Native CUDA acceleration
- Limited by 16GB-24GB VRAM ceiling
- Ideal for 3B-7B models at high speed
Apple M-Series Setup
- Unified memory up to 128GB+
- Lower raw TPS than top-tier NVIDIA
- Can run 70B models locally
- Efficient Metal Performance Shaders (MPS)
Implementation Guide: Setting up Your Private Pipeline
Getting these models running is simpler than ever. Tools like Ollama and LM Studio have removed the need for complex Python environments. You can pull a model with a single command and begin interacting with it via a local API. For developers, integrating these models into existing workflows is the next step. You can use the OpenAI-compatible endpoints provided by these tools to swap cloud models for local ones in your code with zero changes to your logic.
Automating your development cycle with local AI is a massive productivity booster. For instance, using a local Qwen instance for GitHub PR management allows you to analyze codebases without exposing intellectual property. This aligns with modern workflows discussed in our article on 5 AI Coding Assistants for Autonomous GitHub PR Management (2026). Monitoring your performance metrics helps you fine-tune your setup for the best results.
Privacy Governance in Local LLM Deployment
The ultimate benefit of local models is the removal of the third-party middleman. In a world where data leaks are common, keeping your inference local is the only way to ensure 100% privacy. Corporate compliance departments are increasingly mandating local execution for any task involving PII or trade secrets. By deploying these lightweight models, you create a "clean room" environment where AI can assist in the most sensitive parts of your business.
Future-proofing your AI strategy means building for the edge. As these small models continue to improve, the gap between cloud intelligence and local performance will shrink. Developers who master local deployment today will be ahead of the curve when edge AI becomes the default standard for enterprise applications. Security and speed are no longer trade-offs; they are the dual pillars of the local AI movement.