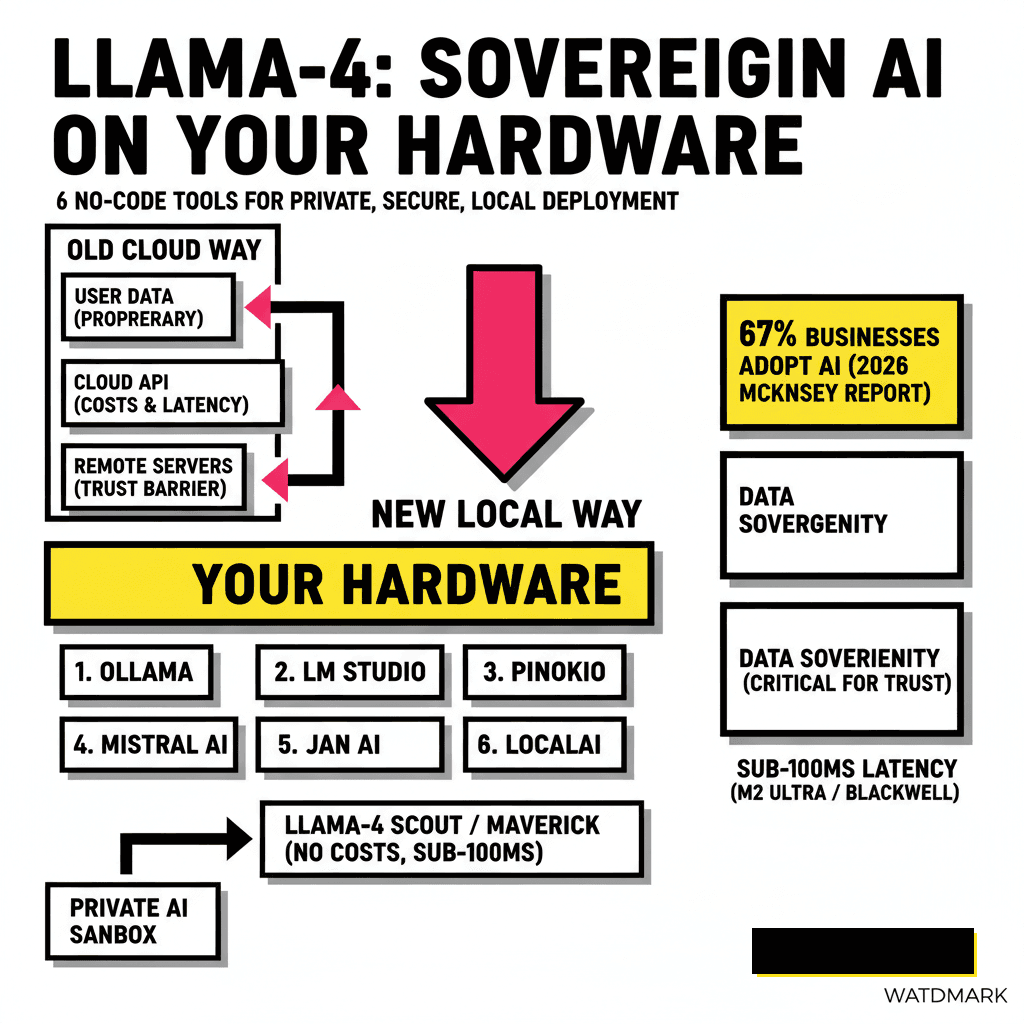
The Sovereign AI Era: Why Llama-4 Belongs on Your Hardware
Data sovereignty has shifted from a niche developer concern to a mandatory business requirement in 2026. Meta released the Llama-4 family on April 5, 2025, introducing the Scout and Maverick models which utilize a sophisticated Mixture-of-Experts (MoE) architecture. While cloud providers offer these models via API, the real power lies in local execution. Running Llama-4 locally eliminates recurring token costs and ensures your proprietary data never leaves your infrastructure. According to a 2026 McKinsey report, 67% of businesses have now adopted some form of generative AI, yet trust remains a primary barrier to scaling. Local deployment solves this trust gap by providing a private sandbox for your most sensitive operations.
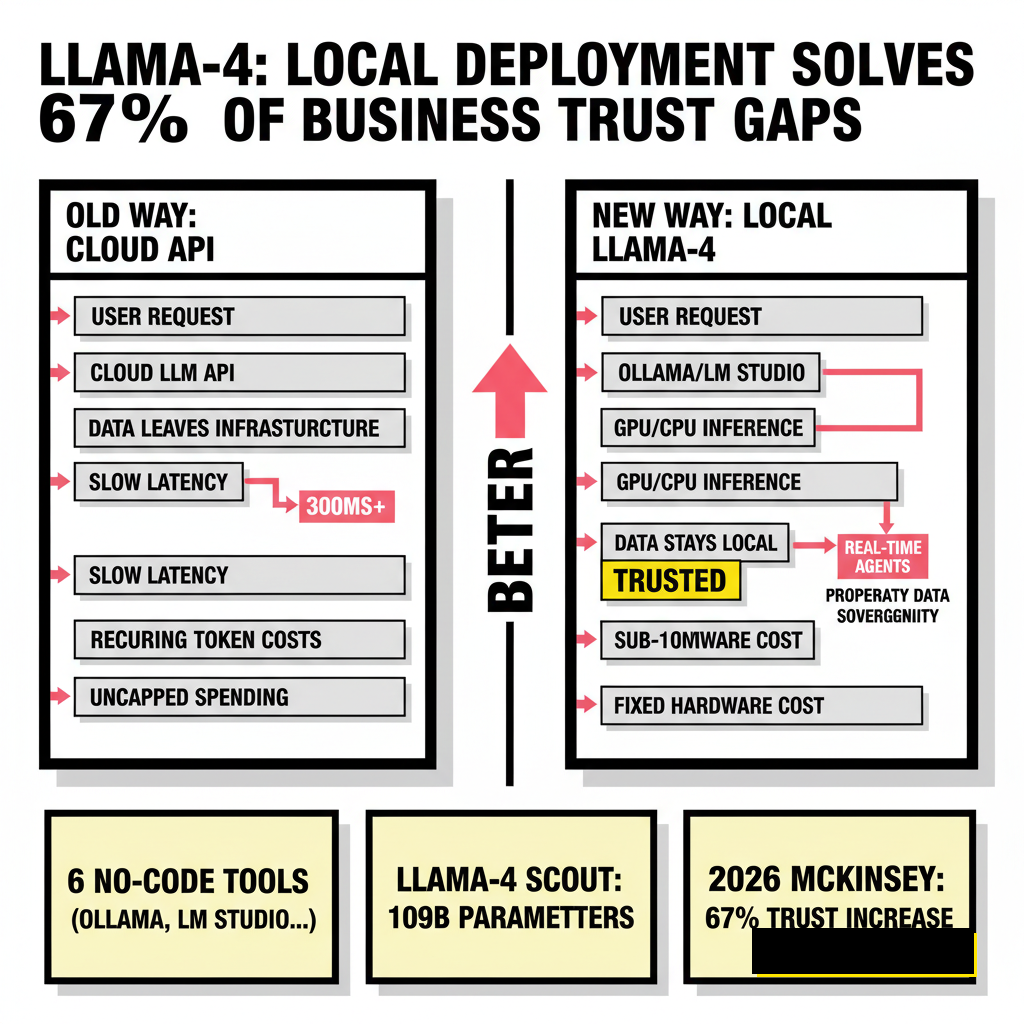
Privacy isn't the only driver for the local movement. Latency in agentic workflows has become a critical bottleneck for developers. When an autonomous agent makes dozens of LLM calls to complete a single task, the 300ms round-trip of a cloud API adds up to significant delays. Modern silicon, particularly Apple's M-series Ultra chips and NVIDIA's Blackwell consumer cards, can now handle Llama-4 Scout with sub-100ms response times. If you're building systems based on autonomous GitHub PR management, local inference provides the speed necessary for real-time code analysis without the latency of the cloud.
1. Ollama: The Developer Standard for Local Inference
Ollama remains the most popular foundation for local LLM execution. It manages the complexities of model weights, quantization, and hardware acceleration through a simple interface. Although it started as a command-line tool, the 2026 ecosystem of no-code wrappers has made it accessible to everyone. You simply download the installer and then use a desktop client like Open WebUI to interact with the model. Ollama handles the heavy lifting of loading Llama-4 Scout's 109 billion parameters into VRAM while efficiently managing the 17 billion active parameters required for each token generation.
Ollama's primary advantage is its stability. The library is optimized for the latest GGUF formats, allowing you to run Llama-4 on a wider range of hardware than official Meta implementations. Developers often pair Ollama with local agents to handle repetitive tasks. This setup ensures that your API keys are never exposed and your usage remains uncapped. You can find the official installation guides and the latest model library at Ollama.com.
2. LM Studio: Visual Model Management for Prototyping
LM Studio provides the most polished graphical experience for discovering and running local models. It features a built-in search engine that connects directly to Hugging Face, allowing you to find specific Llama-4 quantizations with a single click. The interface provides real-time hardware telemetry, showing exactly how much VRAM and CPU the model is consuming during a chat session. This transparency is vital when testing Llama-4 Maverick, which totals 400 billion parameters and requires careful memory management.
LM Studio Personal
- Free for personal use
- Single-model loading
- Built-in model discovery
- Local HTTP server mode
LM Studio Pro (2026)
- Multi-model orchestration
- MCP plugin support
- Enterprise security features
- Optimized Blackwell support
Navigating the complex world of model versions is simplified here. LM Studio automatically filters models based on your hardware's compatibility, preventing the frustration of downloading a 100GB file that your system cannot run. The software also includes a local server feature that mimics the OpenAI API structure. This means you can drop Llama-4 into any existing application by simply changing the base URL. Visit LMStudio.ai to explore their latest cross-platform builds.
3. Jan.ai: The Open Source, Privacy-First Desktop
Jan.ai distinguishes itself through a commitment to being entirely open-source and offline-first. While other tools might include telemetry or cloud-dependent features, Jan is designed to function in air-gapped environments. This makes it the preferred choice for researchers and enterprise teams handling highly regulated data. The platform has evolved into a full AI workstation in 2026, supporting a robust extension system that allows users to add custom tools and file indexing capabilities without writing a single line of code.
Performance on Jan.ai is bolstered by its custom inference engine, which has been optimized specifically for the MoE architecture of the Llama-4 series. Users can toggle between different precision levels to balance speed and accuracy. The project is highly active on GitHub, with a community that prioritizes transparency and user control. If your goal is to stay compliant with 2026 data residency laws, Jan provides the necessary infrastructure. Check out their documentation at Jan.ai for more details.
4. Pinokio: The One-Click Browser for Local AI Environments
Pinokio functions less like a chat app and more like a specialized browser for AI scripts. It automates the installation of the entire software stack required to run Llama-4, including Python environments, Git repositories, and C++ compilers. For many developers, the hardest part of local AI is managing conflicting dependencies. Pinokio solves this by containerizing each application, allowing you to run multiple AI tools side-by-side without issues. It is the closest experience to a "one-click install" available for complex local setups.
The Pinokio ecosystem includes community-maintained scripts for every major AI release. When Meta drops a new Llama variant, a Pinokio script is usually available within hours to automate the deployment. This tool is particularly useful if you are also exploring AEO tactics to rank in SearchGPT, as it allows you to quickly deploy local testing environments for different search-oriented LLMs. You can download the browser at Pinokio.computer to start exploring the script library.
5. GPT4All: High-Performance Reasoning on Consumer Hardware
GPT4All, developed by Nomic AI, focuses on making large models run efficiently on standard consumer CPUs and GPUs. While other tools might require high-end workstations, GPT4All uses advanced quantization techniques to bring Llama-4 reasoning to laptops and older desktops. The software includes a feature called LocalDocs, which allows you to point the model at a folder of PDFs or text files. Llama-4 then uses this data as its primary knowledge source, creating a private, local knowledge base without any cloud dependency.
Security is a core pillar of the GPT4All philosophy. The application runs entirely on your local machine, and the model weights are verified to ensure they haven't been tampered with. This tool is ideal for individual developers who need a reliable assistant for daily tasks but don't have access to a dedicated server rack. The simplicity of the interface hides a powerful engine capable of handling complex reasoning tasks across a variety of languages and domains.
6. AnythingLLM: The Enterprise Orchestrator for RAG Workflows
AnythingLLM is built for users who need more than just a chat interface. It is a full orchestration platform that excels at Retrieval-Augmented Generation (RAG). You can create separate workspaces for different projects, each with its own specific documents and Llama-4 settings. This allows a single local instance to serve as a research assistant for one project and a coding partner for another. AnythingLLM can use Ollama as its back-end engine, combining the best of both worlds: robust inference and sophisticated document management.
| Tool Name | Primary Strength | Best For |
|---|---|---|
| Ollama | Developer Ecosystem | Backend Infrastructure |
| LM Studio | Polished Visuals | Model Testing |
| Jan.ai | Open Source Privacy | Regulated Industries |
| Pinokio | One-Click Scripts | Complex Stack Setup |
| GPT4All | Consumer Efficiency | Low-Spec Hardware |
| AnythingLLM | Enterprise RAG | Team Workspaces |
Multi-user support is another standout feature of AnythingLLM. You can host a single instance on a local server and allow multiple team members to access Llama-4 through their browsers. This setup provides the convenience of a shared AI assistant with the security of on-premise hosting. As we move deeper into 2026, the ability to manage private AI assets at scale will define the competitive advantage of tech-forward organizations. Selecting the right tool today ensures your infrastructure is ready for the future of sovereign intelligence.

