The Shift to AI-Driven Micro-service Architecture
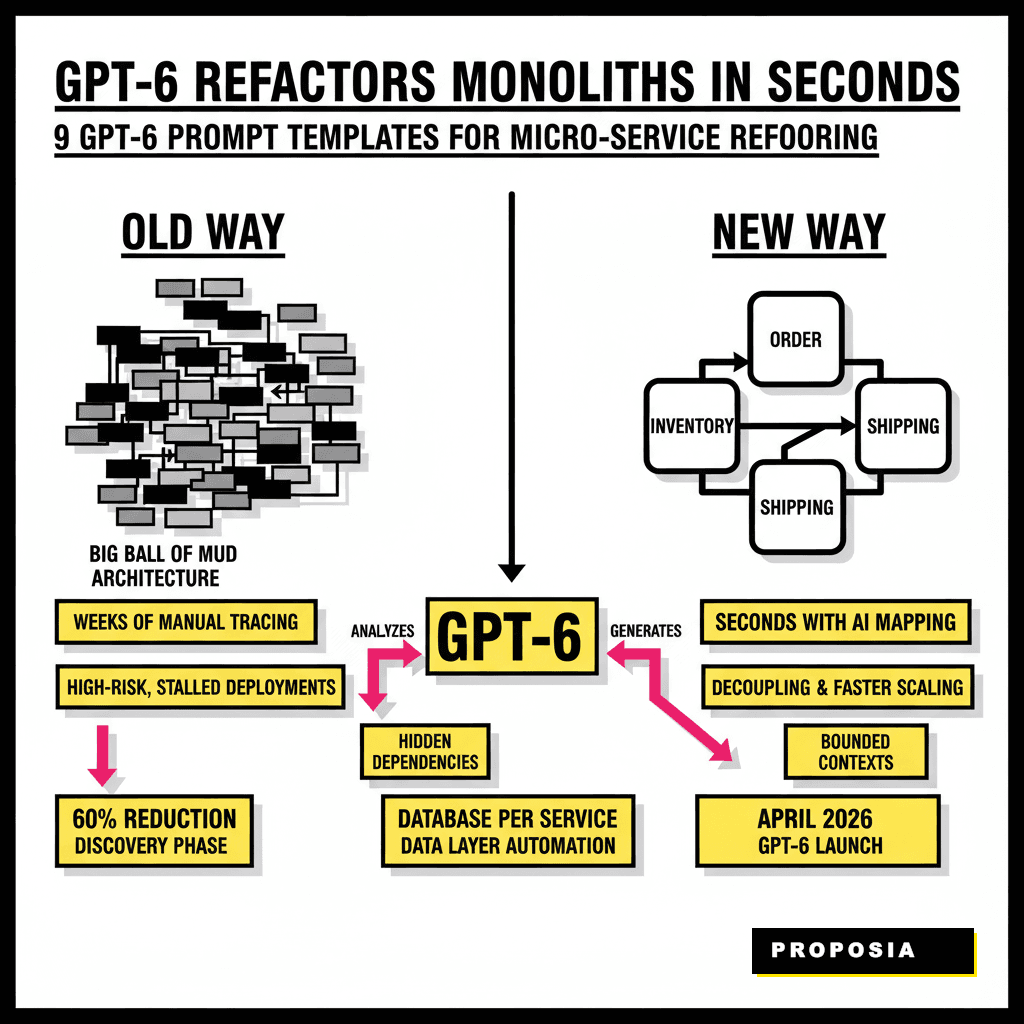
Software engineering is moving past the era where refactoring meant weeks of manual code tracing. By April 2026, the arrival of GPT-6 has changed the baseline for technical debt management. We are no longer just asking AI to write a function. We are asking it to understand the entire topology of a distributed system. Refactoring a monolith into micro-services used to be a high-risk operation that often stalled due to hidden dependencies. Today, the reasoning capabilities of advanced models allow us to map these boundaries in seconds. If you're managing a legacy codebase, you know the weight of a 'big ball of mud' architecture. It slows down deployments and makes scaling specific features impossible. Moving to a micro-service model solves this, but the transition is where most teams fail. These templates provide a structured way to guide the AI through the most difficult parts of that transition.
1. Identifying Bounded Contexts with Domain-Driven Design
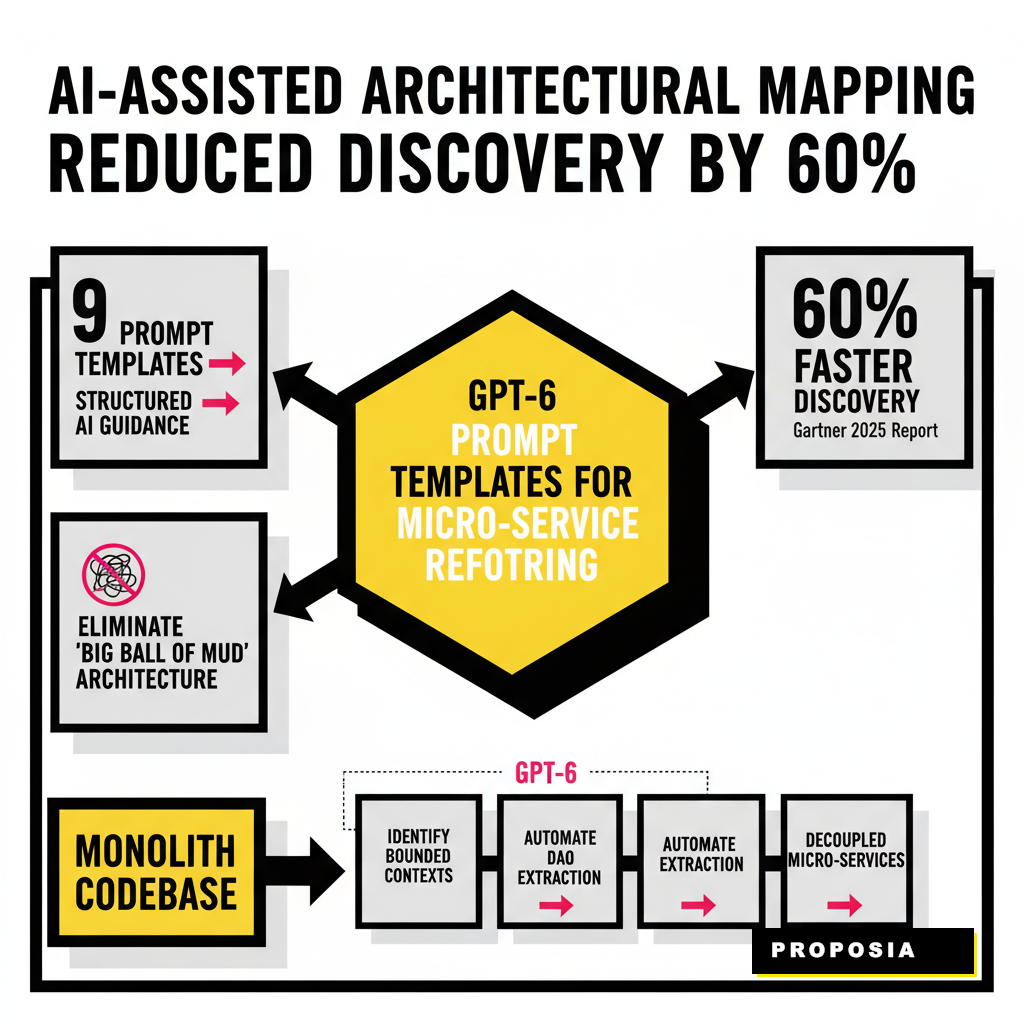
The first step in any refactoring project is deciding where to cut. You can't just split a monolith by folder structure. You need to identify the Bounded Contexts as defined in Domain-Driven Design. GPT-6 is exceptionally good at this because it can ingest your entire repository and identify clusters of logic that share a common language. According to a 2025 Gartner report, AI-assisted architectural mapping has reduced the time spent on discovery phases by 60 percent. This prompt helps you find those logical boundaries without getting lost in the weeds of helper functions. You'll want to provide the model with your directory tree and a summary of your main data models. The goal is to see where the 'Order' logic stops and the 'Inventory' logic begins. Use this template to generate a high-level service map.
Monolith Analysis
- Analyze provided codebase for high coupling.
- Identify shared data entities across modules.
- Highlight circular dependencies in service calls.
Micro-service Proposal
- Define 3-5 distinct service boundaries.
- List proposed API endpoints for each service.
- Suggest an event-driven communication strategy.
2. Automating Data Access Object (DAO) Extraction
Once you know where the service boundaries are, you have to deal with the data layer. In a monolith, every service likely hits the same giant database. Micro-services require 'Database per Service' to ensure true independence. This is technically challenging because you have to untangle foreign key constraints and shared tables. You can use GPT-6 to generate the new repository patterns and data access objects for the new service. It can look at your existing SQL schema or ORM models and rewrite them for a standalone database instance. This process often includes creating Data Transfer Objects (DTOs) to handle the communication between the new service and the old monolith. If you've used specialized GPT-5 assistants in the past, you'll find GPT-6 handles the multi-file context much more reliably.
| Refactoring Task | GPT-6 Prompt Strategy |
|---|---|
| Schema Splitting | Identify tables used by service X and generate SQL migration scripts. |
| DTO Generation | Create JSON serializable classes from existing internal entities. |
| Repository Pattern | Convert direct SQL queries into a clean abstraction layer for the new service. |
3. Generating Sidecar and Service Mesh Configurations
Micro-services don't live in a vacuum. They need service discovery, mutual TLS, and traffic management. For beginners, setting up a service mesh like Istio or Linkerd is often the hardest part of the project. GPT-6 can generate the YAML configurations for your sidecar proxies based on the service map you created earlier. It understands the nuances of Kubernetes manifests and can ensure your resource limits and probes are correctly defined. This reduces the chance of 'death by YAML' where a single indentation error brings down your cluster. Many developers are now integrating these configurations into agentic workflows to keep their infrastructure as code (IaC) in sync with their code changes. Werner Vogels, CTO of Amazon, frequently notes that the best way to handle complexity is to automate the mundane parts of infrastructure. These prompts do exactly that.
4. Implementing Circuit Breakers and Resilience Patterns
When you move to micro-services, network reliability becomes a concern. A single slow service can cause a cascading failure across your entire system. You must implement patterns like Circuit Breakers and Retries. Writing these manually across twenty different services is tedious and prone to inconsistency. GPT-6 can take a standard library like Resilience4j or Polly and wrap your service calls with the appropriate logic. This ensures that if the 'Payment Service' is down, the 'Order Service' doesn't hang indefinitely. It can also suggest reasonable timeout values based on the typical latency of the cloud provider you are using. A 2026 report from the Cloud Native Computing Foundation highlights that resilience is the top priority for 74 percent of engineering teams moving to the cloud. Using AI to standardize these patterns across your fleet is a major win for stability.
5. Creating Automated Contract Tests
One of the biggest risks in micro-services is breaking the API contract between two services. If Service A changes its response format, Service B might crash. Contract testing ensures that both sides agree on the interface. GPT-6 can look at the API definition of a service and automatically generate Pact or Postman tests. This ensures that your refactoring doesn't break existing functionality. Beginners often skip this step because it feels like extra work. However, with AI, you can generate an entire test suite in the time it takes to write a single manual test case. This is crucial for maintaining a high deployment velocity. You can find more about how AI handles these detailed verification tasks in our guide on AI search optimization tactics, which discusses the underlying reasoning patterns of modern LLMs.

Getting Started with the Templates
Refactoring isn't a one-time event. It is a continuous process of keeping your code clean as your business grows. The 9 templates we've discussed cover the spectrum from initial boundary discovery to final testing. To use them effectively, always start with a small, low-risk module. Don't try to refactor your core billing engine on day one. Pick a peripheral service like 'Notifications' or 'Logging' and run it through the GPT-6 prompts. This will give you a feel for how the model handles your specific coding style and architecture. As you gain confidence, you can move toward more complex services. Remember that AI is a co-pilot. You still need to review the generated code, especially for security and performance. For teams looking to secure their deployments, checking out AI privacy agents can provide additional layers of data protection during the refactoring process.

