The Shift from Static Bots to Autonomous Intelligence
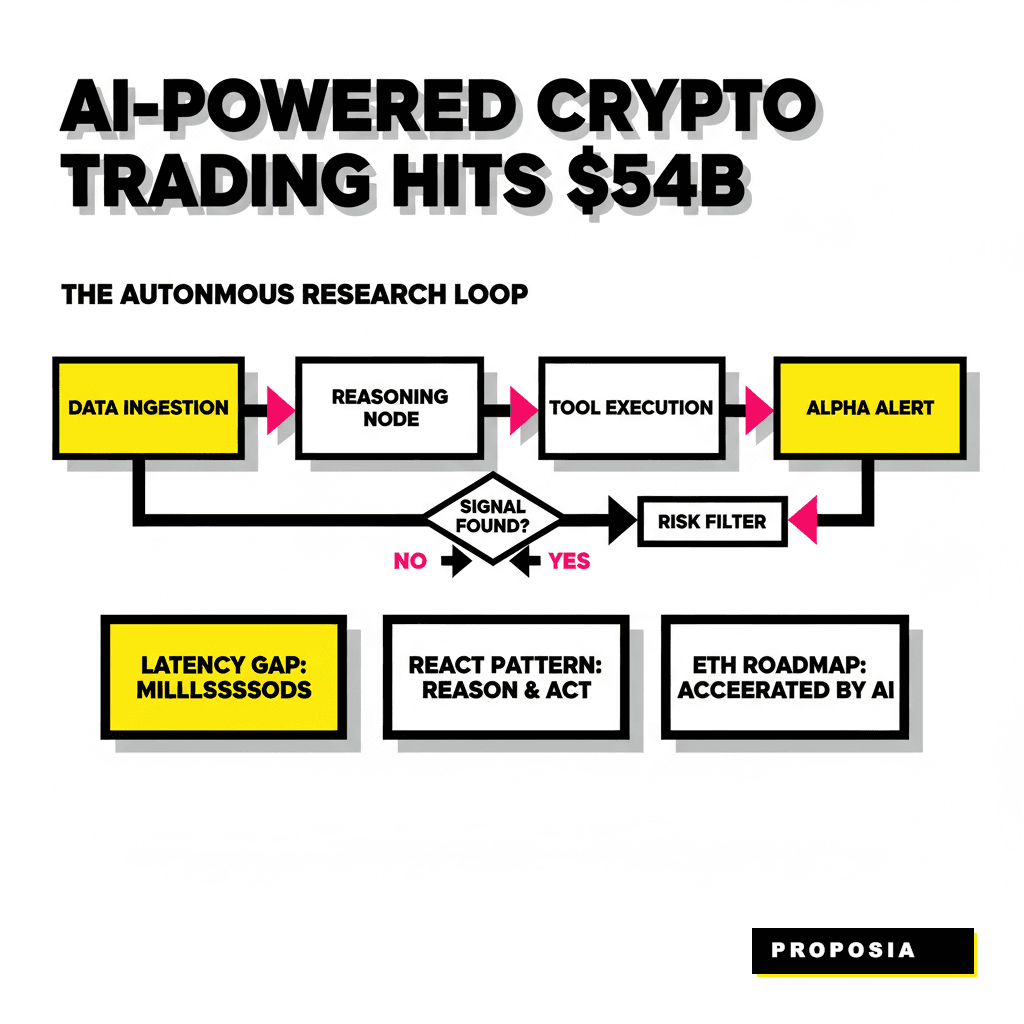
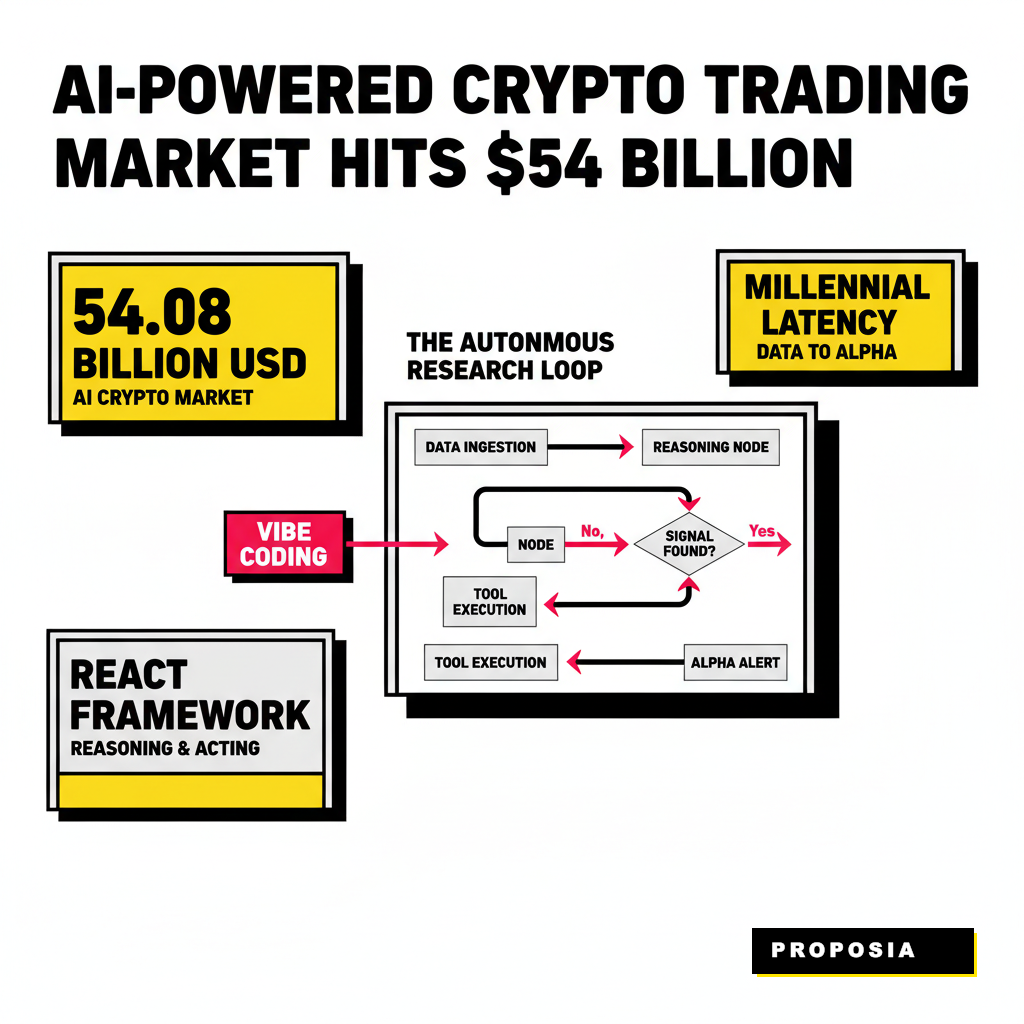
Building a crypto research tool used to mean writing a few Python scripts that scraped Twitter or polled a price API every sixty seconds. Those days ended when the latency gap between raw data and actionable alpha narrowed to milliseconds. You need a system that doesn't just react to price changes but actively reasons about why they are happening. Our goal is to move past the rigid logic of traditional trading bots and toward a reasoning engine capable of identifying patterns before the broader market catches on. According to a 2026 report by Business Research Insights, the AI-powered crypto trading market has grown to roughly 54.08 billion USD, signaling a massive migration toward automated intelligence. If you are still relying on manual dashboards, you are essentially fighting a high-frequency battle with a wooden shield.
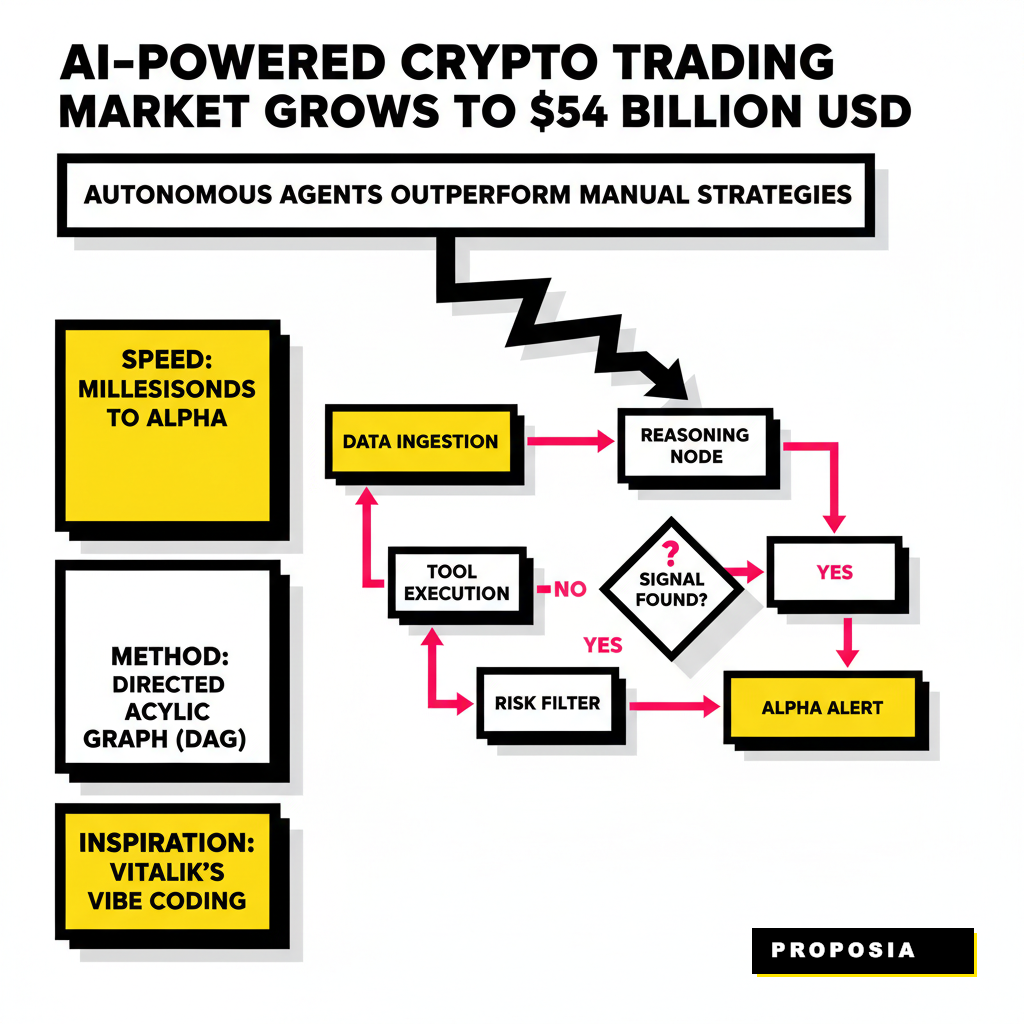
Autonomous agents operate by maintaining a persistent state and utilizing tools to interact with the environment. Unlike a standard LLM call that forgets the context immediately, a research agent uses a directed acyclic graph to manage its thoughts. You can think of this as a shared whiteboard where different specialized functions write their findings. One node might monitor whale movements while another scans for new liquidity pool deployments. They collaborate, cross-reference, and eventually arrive at a high-confidence signal. This architecture allows the system to handle complex, non-linear tasks like evaluating a developer's previous project history or checking the contract's minting permissions in real-time. By the time a human finishes reading a single tweet, an autonomous agent has already audited the contract, checked the founder's wallet history, and assessed the current sentiment across four different social platforms.
The Core Architecture of an Alpha Agent
Your agent's brain requires a structured workflow to avoid getting lost in the noise of the blockchain. We utilize a pattern known as ReAct, which stands for Reasoning and Acting. Every loop begins with an observation. The agent pulls data from an API, then thinks about what that data implies, and finally decides which tool to use next to confirm its hypothesis. Vitalik Buterin recently noted that AI is massively accelerating coding and that the community should expect the Ethereum roadmap to finish faster than expected because of these autonomous workflows. He described this as vibe coding, a process where high-level intent is translated into secure, functional code by AI assistants. Our research agent applies this same philosophy to discovery, focusing on high-level alpha targets rather than manual query construction.
The orchestration layer is where you define the rules of engagement. Using LangGraph documentation as a reference, we can build a stateful system that manages context across multiple turns. This approach prevents the agent from repeating the same API calls and ensures that every new piece of information builds upon the previous one. You might start with a simple prompt like find me tokens with high smart money inflow in the last hour. The agent doesn't just return a list. It initiates a multi-step process: query Nansen for the addresses, query Dune for the liquidity depth, and use a specialized model to scan the contract for common vulnerabilities. If you want to see how this fits into a larger micro-service structure, check out our guide on 9 GPT-6 Prompt Templates for Micro-Service Refactoring to see how to modularize these nodes for production.
Data Ingestion: Connecting to Real-Time Streams
An agent is only as smart as the data it consumes. For crypto alpha, you cannot rely on periodic scrapes. You need direct access to the mempool and live event logs. Providers like Nansen's API offer proprietary data labeling that identifies market makers, exchanges, and smart money wallets. This context is vital because a 100,000 USD buy from a retail wallet means something very different than a 100,000 USD buy from a known venture fund. Integrating these labels directly into your agent's toolset allows it to filter out the noise and focus on the entities that actually move the market. You are effectively giving your AI the eyes of a professional on-chain analyst who never sleeps.
Dune Analytics recently launched a DeFi Positions API that provides real-time position data across seven EVM chains in under one second. This level of speed is the baseline for 2026. Your agent should use these endpoints to monitor institutional health. If a major lending protocol begins to see a massive outflow of collateral, your agent can detect the trend before the news hits Twitter. We can also utilize specialized prompts to help the agent interpret this raw data. For instance, you could use some of the techniques from our article on 12 Zero-Code Prompts for Specialized GPT-5 Assistants to create a sub-agent that specifically analyzes liquidity health. By delegating the heavy lifting of data parsing to specialized nodes, the main reasoning engine can stay focused on the high-level strategy.
Implementing the Reasoning Loop with LangGraph
The implementation phase involves defining your graph state. In Python, this is typically done using a TypedDict that keeps track of the conversation history, retrieved documents, and the current hypothesis. Every node in your graph is a function that takes the current state and returns an update. This modularity makes it easy to swap out a local model for a more powerful cloud-based LLM if the task requires deeper reasoning. You don't want a massive monolithic script. You want small, testable nodes that do one thing well, such as checking a token's social media velocity or auditing a smart contract for reentrancy bugs.
Step 1: State Definition
- Define a TypedDict to track the research context.
- Include fields for latest on-chain events and social sentiment.
- Maintain a running list of 'Alpha Score' metrics.
Step 2: Node Logic
- Create specialized nodes for SQL querying and web searching.
- Implement an 'Evaluator' node to score potential signals.
- Add a 'Reporter' node to format findings for the end user.
Concurrency is your best friend when building these systems. While the reasoning engine is deciding on the next step, your data ingestion nodes should be pre-fetching the latest blocks. Using asynchronous Python allows your agent to query multiple APIs simultaneously, significantly reducing the time it takes to validate a signal. If the agent detects a surge in activity on a decentralized exchange, it can spawn parallel tasks to check the token's top holders on Etherscan and analyze the sentiment on Telegram. This multi-threaded approach ensures that your agent is always working with the most up-to-date information possible. It isn't just about finding the data; it's about finding it before anyone else does.
Filtering Noise: Risk Management and Signal Validation
The crypto market is famous for its noise. Fake volume, wash trading, and honeypot scams are everywhere. An autonomous agent that blindly follows every buy signal will quickly lose its entire treasury. You must implement a strict risk management layer that acts as a gatekeeper. This layer should look for red flags like low liquidity-to-market-cap ratios or contracts where the owner can arbitrarily pause trading. According to 2026 industry statistics, automated trading adoption has risen significantly, yet 28% of users still report vulnerabilities as their primary concern. Your agent needs to be a skeptic by default.
We can solve this by creating a dedicated validation node that scores every potential alpha lead. This node should check the project's longevity, the consistency of its developer activity, and the distribution of its token holders. If the top ten wallets hold more than 50% of the supply, the agent should automatically downgrade the signal's confidence score. This objective, data-driven approach removes the emotional bias that often leads human traders into traps. You are building a machine that values cold, hard metrics over the excitement of a trending ticker. When the agent finally presents a lead, you know it has survived a gauntlet of rigorous checks.
Deployment and Orchestration at Scale
Once your agent is functional, the next challenge is running it 24/7 without it becoming a cost center. Deploying these agents as serverless functions or within Docker containers on a cloud provider is the most scalable path. You need a robust logging system to monitor the agent's reasoning process and catch any runaway loops before they drain your API credits. Many developers are now moving toward multi-agent swarms where a manager agent oversees several worker agents, each focused on a different blockchain or asset class. This hierarchical structure allows for massive horizontal scaling without overwhelming the main reasoning engine.
| Provider | Best For | Key Feature |
|---|---|---|
| Nansen | Smart Money Tracking | Proprietary Wallet Labels |
| Dune Analytics | Protocol Deep Dives | Real-Time DeFi Positions API |
| Glassnode | Market Cycle Analysis | On-Chain Supply Dynamics |
The final piece of the puzzle is the feedback loop. Your agent should learn from its successes and failures. By storing the results of past signals in a vector database like Pinecone or Weaviate, the agent can perform a retrospective analysis to see which indicators were the most predictive of price action. Over time, the system will refine its own parameters, becoming more efficient at spotting true alpha and ignoring the noise. This self-improving nature is what separates a true autonomous agent from a simple script. You aren't just building a tool. You are building an evolving intelligence that grows more capable with every block added to the chain. The future of crypto research belongs to those who can automate the intuition of the world's best analysts.

