If you are building AI-powered applications or agentic workflows in 2026, you have likely wrestled with the ultimate developer dilemma: should you build on OpenAI’s GPT models or Anthropic’s Claude?
For years, OpenAI was the default choice. However, a massive architectural pivot is happening in the software engineering community. Developers are quietly but rapidly migrating their production workloads to Anthropic's Claude Opus line—most recently, the newly released Claude Opus 4.7.
If you want to build scalable, bug-free applications without burning through your API budget, here is the data-driven truth about why Claude is dominating the AI coding landscape, and how open-source models are finally catching up.
1. The "Programmatic Laziness" Epidemic
A primary driver of the massive migration toward Claude is the developer community's growing frustration with what is known as "laziness" in the GPT series.
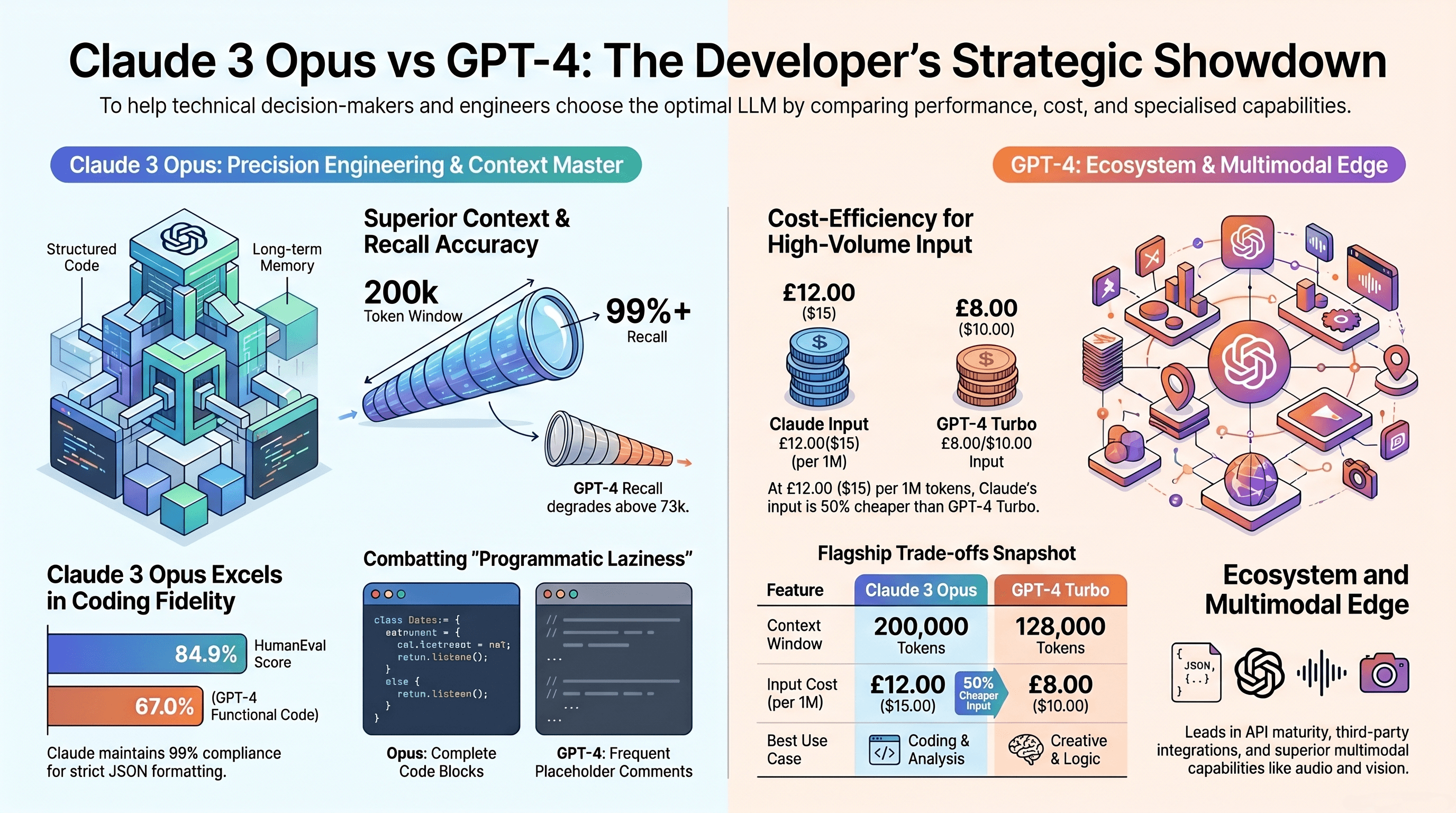
Since the GPT-4 Turbo days, developers have consistently reported that OpenAI models often provide incomplete code blocks. Instead of generating a full, functional script, GPT will often output placeholders like //... (rest of code here) or /* implement logic here */. This forces developers to manually fill in the gaps or waste tokens on multiple follow-up prompts.
Claude Opus, by contrast, is a workhorse. It is known for outputting 250 to 350 lines of complete, working code in a single turn. Developers liken GPT to an "offshore programmer" who requires constant supervision, while Claude Opus acts like a senior contractor who thoroughly thinks through the entire solution before delivering it ready for production.
2. Real-World Benchmarks: Opus 4.7 Crushes GPT-5.4
In the world of AI coding, theoretical benchmarks mean nothing if the code doesn't actually run. Recent independent benchmarks testing real-world Ruby on Rails application generation expose a massive gap between the newest frontier models.
In a head-to-head automated benchmark, Claude Opus 4.7 emerged as the gold standard. It produced clean, functional implementations with comprehensive test coverage, costing approximately $1.10 per run. Opus 4.7 also scored an industry-leading 87.6% on the SWE-bench Verified coding benchmark, cementing its status as the king of agentic coding.
Meanwhile, GPT-5.4 (via Codex) proved to be an expensive disappointment. While it generated a highly sophisticated software architecture, it completely failed on multi-turn interactions because it hallucinated the wrong calling convention for the required API (using keyword arguments instead of a positional hash).
The cost difference was staggering: GPT-5.4 burned through 7.6 million tokens on maximum reasoning effort, costing roughly $16.00 per run—nearly 15 times more expensive than Opus 4.7—and it still got the API integration wrong.
3. Context Windows That Actually Remember
For complex enterprise applications, your AI needs to process massive codebases without forgetting crucial details.
GPT models technically offer context windows up to 128K (and extended 1.05M contexts), but independent evaluations reveal that their recall performance degrades significantly once the document length exceeds 73,000 tokens.
Claude Opus, however, boasts near-perfect recall (over 99% accuracy) across its massive context windows. With the release of Claude Opus 4.6 and 4.7, Anthropic introduced a 1-million token context window that allows developers to load almost their entire codebase into the model's memory. This means Claude can track complex inter-dependencies between multiple files—like how a frontend React component impacts a backend API—without hallucinating or losing the plot halfway through a debugging session.
4. Strict Instruction Following (No More "AI Slop")
When you are building automated pipelines, you need an AI that follows strict formatting rules. If you ask an LLM to output "ONLY JSON," you cannot afford for it to add a conversational preamble like "Here is the JSON you requested:" because it will instantly break your application parser.
In strict instruction following tests, Claude demonstrated a 99% compliance rate, outputting exactly what was requested without the extra conversational filler. Claude Opus 4.7 is specifically tuned to interpret prompts incredibly literally, ensuring predictable behavior for enterprise API integrations.
5. The Open-Source Threat: GLM-5 is the Ultimate Budget Hack
What if you want to escape vendor lock-in entirely? The open-source landscape has evolved drastically by 2026, but you need to be careful.
Many heavily-hyped open-source models, such as Qwen 3 Coder or DeepSeek V3.2, completely fail at real-world coding because they hallucinate non-existent API endpoints. Even models distilled directly from Claude's reasoning traces successfully mimic Claude's coding style but fail to retain its factual knowledge, resulting in elegant code that immediately crashes.
However, there is a hidden gem for budget-conscious developers: GLM-5 and GLM-5.1. These open-source models successfully completed complex coding benchmarks, generating correct APIs and working tests for a fraction of the price. GLM-5 costs roughly $0.11 per run—an 89% discount compared to Claude Opus—making it the ultimate plug-and-play alternative for developers who need high quality without the Anthropic or OpenAI price tag.
The Final Verdict: Which LLM Should You Use?
Choosing the right model in 2026 comes down to routing tasks based on cost and complexity:
For maximum quality, complex architectures, and agentic coding: Use Claude Opus 4.7. It is the undisputed king of software engineering tasks, offering deep reasoning and perfect instruction following.
For high-volume, cost-sensitive production workloads: Use Claude Sonnet 4.6. It delivers 98% of Opus's coding quality at a fraction of the cost, running at an incredibly fast 532 tokens per second.
For creative writing, marketing copy, and multi-modal inputs: GPT-5.4 and Gemini 3.1 Pro still hold the edge in creative prose, storytelling, and native audio/visual integrations.
To escape API costs entirely: Deploy GLM-5.1 for open-source coding that actually works.
The era of defaulting to OpenAI for every task is officially over. The developers shipping the fastest, most reliable software in 2026 have recognized that when it comes to deep reasoning and reliable code generation, Claude Opus is simply in a league of its own.

