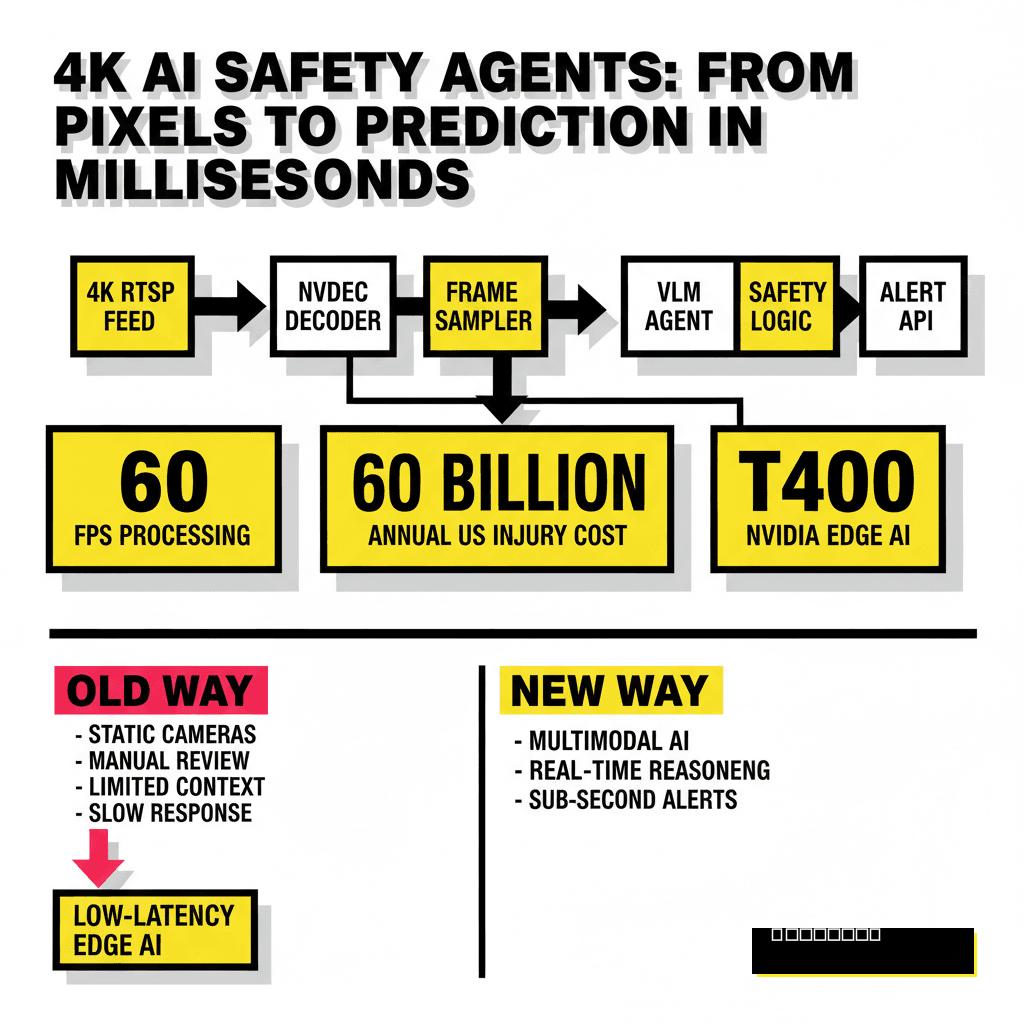
The High-Stakes Shift to Multimodal Safety Agents
Industrial safety is no longer just about static cameras and manual review. Traditional computer vision systems often struggle with context, failing to distinguish between a worker leaning over a rail and someone actually falling. Modern facilities now require agents that can see, reason, and act within milliseconds. Moving to 4K resolution provides the granular detail needed for PPE detection at distance, but it also introduces massive data throughput challenges. Building a system that processes these feeds in real-time requires a departure from simple object detection toward multimodal reasoning.
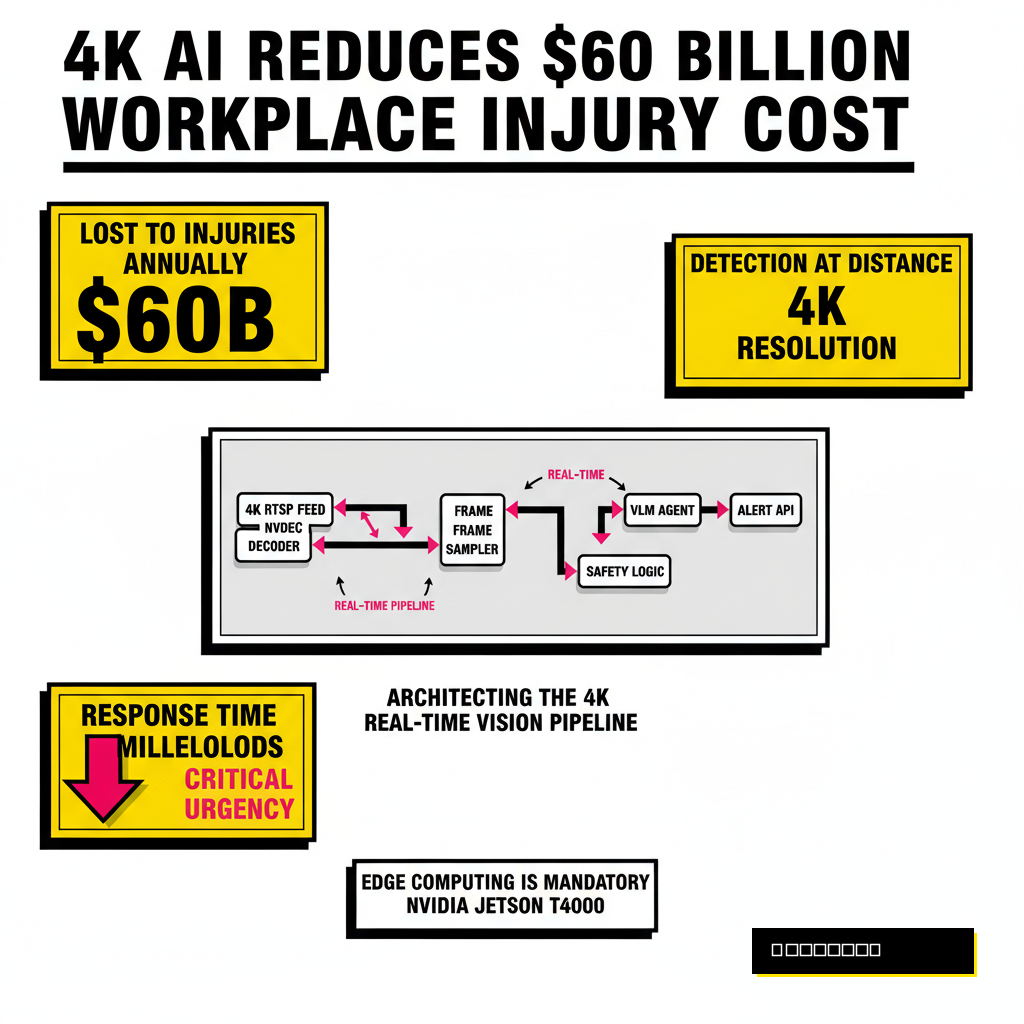
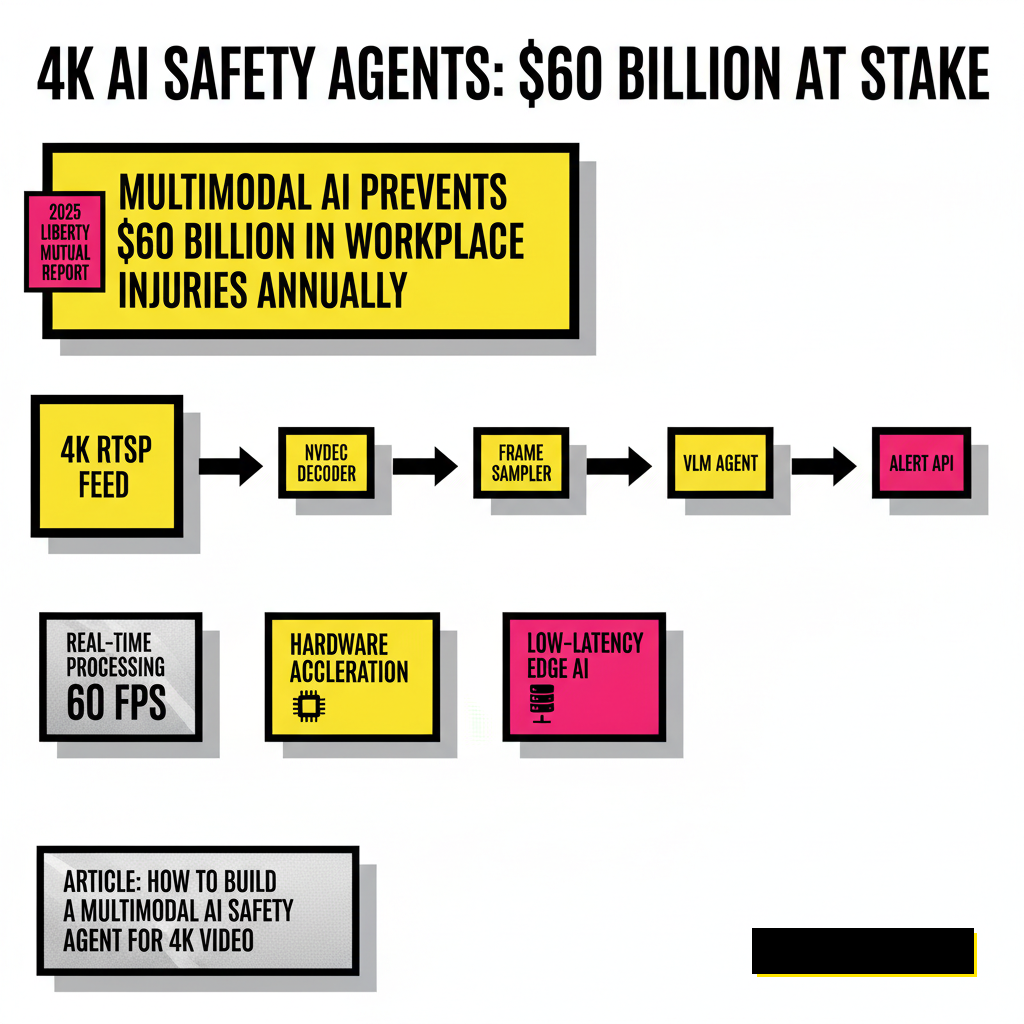
Workplace safety carries a massive financial burden. According to the 2025 Liberty Mutual Workplace Safety Index, serious non-fatal injuries cost U.S. employers nearly $60 billion annually. Most of these incidents result from human error or fatigue, factors that simple motion sensors cannot detect. Multimodal AI agents bridge this gap by analyzing visual data alongside temporal context. Instead of just flagging a person near a machine, the agent understands if the machine is powered on and if the person is wearing the correct gloves for that specific task.
Architecting the 4K Real-Time Vision Pipeline
Processing 4K video at 60 frames per second requires a highly optimized ingestion engine. You cannot simply pipe raw pixels into a Large Language Model (LLM) and expect low latency. The architecture must separate the heavy lifting of video decoding from the cognitive work of multimodal reasoning. Using hardware-accelerated codecs is non-negotiable here. A typical pipeline starts with an RTSP stream, moves through a dedicated decoder, and then undergoes frame sampling before reaching the inference core.
Efficiency depends on how you handle the visual tokens. Standard Vision Transformers (ViTs) can become a bottleneck when dealing with high-resolution inputs. Smart sampling techniques, such as region-of-interest (ROI) cropping, allow the agent to focus its reasoning power on the most relevant parts of the 4K frame. This approach maintains the high resolution where it matters without overwhelming the model's context window. Developers often use a dual-stage process where a lightweight model detects movement, and the multimodal agent performs the final safety audit.
Selecting Hardware for Low-Latency Inference
Edge computing is the only viable path for 4K safety agents where sub-second response times are mandatory. Sending 4K raw streams to the cloud introduces too much jitter and bandwidth cost. The release of the NVIDIA Jetson T4000 in early 2026 has changed the math for local deployments. This module provides 1200 FP4 TFLOPs of compute, which is enough to run sophisticated Vision-Language Models (VLMs) directly on the factory floor.
Local processing ensures that safety systems remain functional even if the facility loses external connectivity. Privacy is another critical factor. Keeping video data within the local network helps satisfy strict labor union requirements and data residency laws. If you are looking for specific models to deploy on this hardware, check out our guide on 6 lightweight LLMs you can run locally. These smaller models often serve as the reasoning backbone for real-time agents when paired with a vision encoder.
Integrating VLMs for Complex Safety Reasoning
Traditional object detection tells you that a forklift is present. A multimodal agent tells you that the forklift driver is distracted by a mobile phone while approaching a blind corner. This level of understanding requires a Vision-Language Model that can interpret intent and environmental context. Implementing this logic involves moving beyond simple threshold-based alerts. You need to craft prompts that force the model to evaluate the scene against specific safety protocols.
| Model Tier | Detection Latency | Reasoning Depth |
|---|---|---|
| YOLOv11+ (CV Only) | ~10ms | Low (Labels only) |
| Small VLM (Edge) | ~150ms | Medium (Action context) |
| Agentic VLM (Cluster) | ~300ms | High (Multi-step logic) |
Reasoning latency is the biggest hurdle in 2026. While the Blackwell architecture has significantly dropped the cost per token, complex chains of thought still take time. We have found that using System-2 thinking prompts can drastically improve the accuracy of these agents by forcing them to verify their own observations. For example, the agent might first identify a liquid on the floor and then cross-reference it with the nearby chemical storage labels to determine the severity of the spill.
Optimizing Throughput and Compliance Loops
Building the agent is only half the battle. Deploying it into a production environment requires a robust feedback loop for compliance and continuous improvement. Every time the agent flags a safety violation, the event should be logged with the associated 4K frames and the model's reasoning trace. This documentation is vital for OSHA audits and for fine-tuning the model over time. Modern systems use a human-in-the-loop (HITL) approach where safety managers review flagged events to correct false positives.
Edge Deployment
- Minimal latency (< 300ms)
- Zero data transit costs
- Operates without internet
- Lower compute overhead
Cloud Hybrid
- Infinite scaling capacity
- Easier model updates
- Centralized data logging
- High bandwidth required
Security is paramount when dealing with live 4K video. Implementing end-to-end encryption for the RTSP streams and using secure enclaves for inference protects the visual data from unauthorized access. As these agents become more autonomous, their decisions must be explainable. Using a multimodal agent that outputs both a bounding box and a natural language explanation of the hazard helps build trust with the workforce. Transparency ensures that workers view the AI as a protective tool rather than a surveillance mechanism.
Maintaining an agent at this scale requires a focus on reliability. Hardware-level monitoring of the GPU and NPU temperatures is necessary when running continuous 4K inference. Developers often implement a watchdog service that can reboot the vision pipeline if the frame rate drops below a certain threshold. By combining high-resolution visual data with agentic reasoning, industrial facilities can finally move from reactive safety measures to a proactive, automated environment that protects every worker in real-time.

