Defending the Virtual Boardroom Against Synthetic Media
Identity theft used to involve stolen passwords or social security numbers. In 2026, the threat has moved to the face and voice. A stranger can now join your executive Zoom or Teams meeting appearing exactly like your CEO, using high-fidelity generative models to authorize fraudulent wire transfers or extract sensitive intellectual property. Such scenarios are no longer theoretical. Earlier this year, organizations began seeing a massive uptick in sophisticated impersonation attempts that bypass standard multi-factor authentication. Security leaders realize that seeing is no longer believing.
Enterprises need a proactive defense layer that operates directly within the video stream. You can't wait for a post-call forensic analysis to tell you that the person you just spoke with was an AI. Real-time filtering provides the immediate verification required for high-stakes communication. While Microsoft and Google continue their enterprise agentic battle, the responsibility for securing these channels often falls on internal security engineering teams. Building a custom filter allows your organization to own the data and the detection threshold without relying on third-party privacy policies.
The Latency Problem in Live Detection
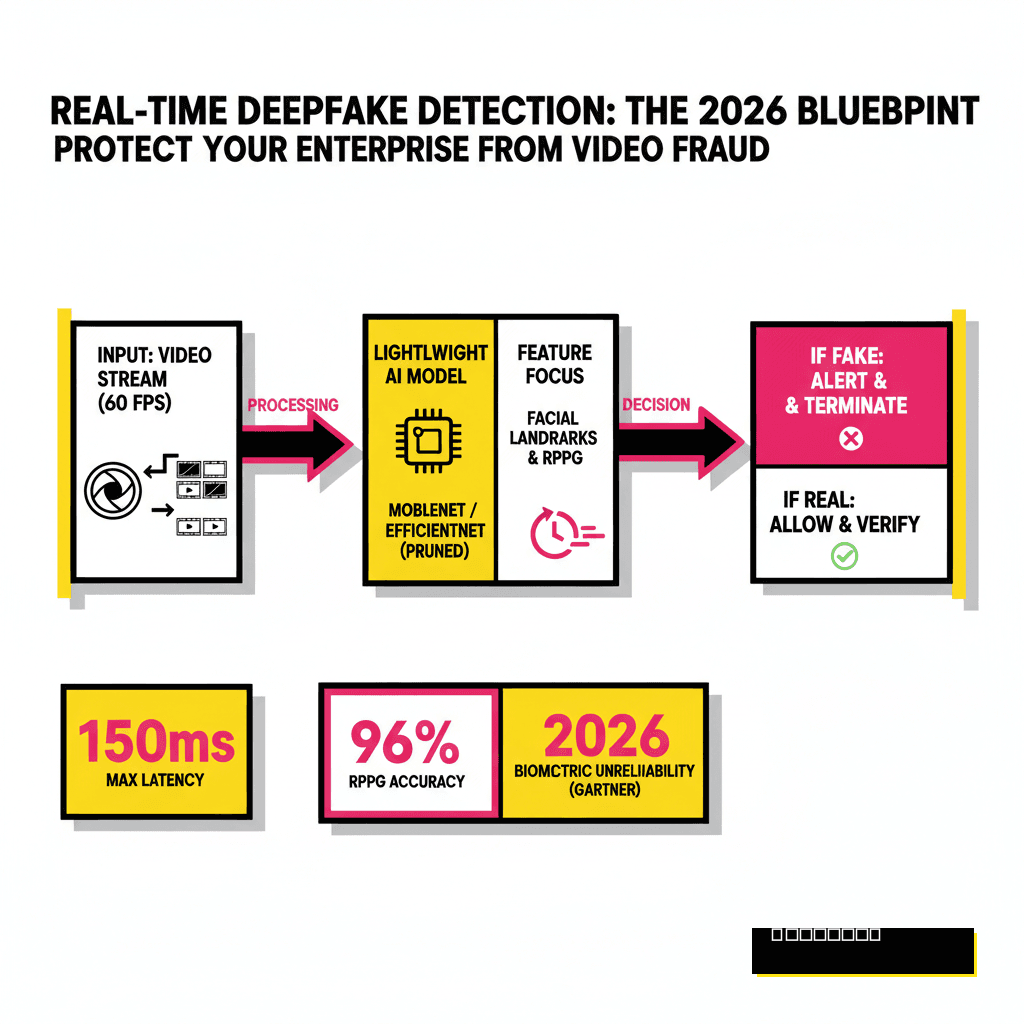
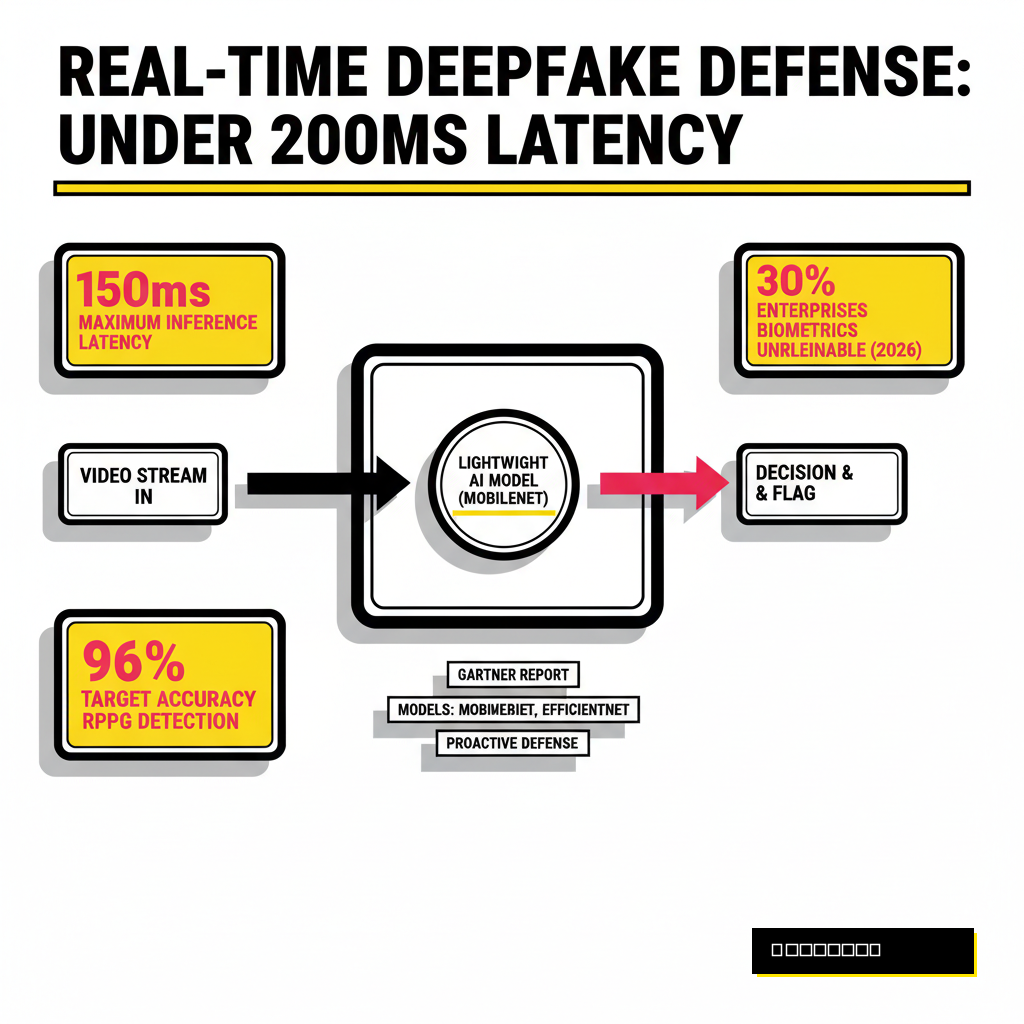
Detection speed is the primary hurdle for any real-time security application. Standard deepfake detection models often take seconds to process a single frame, which is unacceptable for a live 60 FPS video call. If your filter introduces more than 150 to 200 milliseconds of lag, the conversation becomes disjointed and unusable. Effective filters must balance model depth with inference speed. You are essentially racing against the video encoder to flag anomalies before the next packet leaves the network.
Modern systems solve this by utilizing lightweight architectures like MobileNet or custom-pruned versions of EfficientNet. These models focus on specific facial regions rather than the entire frame to save compute cycles. According to a 2026 report from Gartner, roughly 30 percent of enterprises will consider traditional biometric authentication unreliable due to these synthetic advances. Your goal is to keep the detection overhead low enough that it feels invisible to the user while maintaining a high enough accuracy to catch modern generative adversarial networks (GANs).
Comparing Spatial and Temporal Detection Methods
A robust filter looks for two types of errors: spatial and temporal. Spatial analysis examines individual frames for artifacts like blurring around the mouth, mismatched eyes, or unnatural skin textures. Temporal analysis looks at how the face moves over time. Deepfakes often struggle with consistent lighting across frames or the subtle movement of hair. One of the most effective methods involves Remote Photoplethysmography (RPPG). This technique detects minute changes in skin color caused by blood flow, something that current AI models rarely simulate correctly.
Combining these methods creates a multi-layered defense. While a spatial check might catch a low-quality face swap, an RPPG check will flag a high-end diffusion model that lacks a heartbeat signature. Integrating these into your video pipeline requires a strategic choice between checking every frame or sampling at specific intervals. Sampling saves power but might miss a momentary glitch that reveals the fraud. Most enterprise implementations opt for a sliding window approach, analyzing a segment of frames every few seconds to maintain a continuous risk score.
| Detection Method | Strengths | Computational Cost |
|---|---|---|
| Spatial Artifacts | Fast, catches low-tier swaps | Low |
| Audio-Visual Sync | Catches lip-sync mismatches | Medium |
| RPPG (Blood Flow) | Extremely hard to spoof | High |
Building the Detection Pipeline
The technical implementation begins with frame interception. You can achieve this using a virtual webcam driver or by hooking into the WebRTC stream of your conferencing software. Once you have the raw video buffers, the pipeline follows a strict sequence: face detection, feature extraction, and then parallel inference. You don't want your main video thread waiting for the AI to finish. Instead, the detection should run as a background process that updates a 'Trust Score' overlay in the UI.
Using a library like Mediapipe allows for fast facial landmarking, which serves as the foundation for more complex checks. From there, you can pass the cropped face chips to a specialized model like Intel's FakeCatcher or a custom-trained transformer. If the model detects a mismatch, the system can trigger an automated alert to the IT security team or display a warning directly to the meeting participants. For those working with advanced media, you might find similarities in how we process 4K interactive NeRF demos with AI voice, where synchronizing multiple data streams is vital.
Deployment Strategies: Edge vs. Cloud
Choosing where to run the detection model affects both security and performance. Edge deployment, where the model runs on the user's local machine, offers the lowest latency and the best privacy. No video data ever leaves the local environment. However, this requires employees to have relatively powerful hardware, which isn't always feasible for a remote workforce. Cloud-based detection allows you to run much larger, more accurate models, but it introduces significant network latency and potential privacy concerns as raw video must be transmitted to a central server.
Hybrid approaches often provide the best balance. A lightweight model runs on the edge to perform basic liveness checks. If a certain risk threshold is met, the system sends a short clip to a more robust cloud model for a secondary, deeper analysis. This tiered strategy ensures that regular calls remain snappy while high-risk situations get the full weight of your security stack. Your choice here will define how well the system scales across thousands of concurrent corporate users.
Edge Processing
- Zero network latency
- Maximum data privacy
- Lower model complexity
- Hardware dependent
Cloud Processing
- High model accuracy
- Centralized logging
- Significant latency tax
- Privacy risks
Preparing for the Post-Detection World
Detection is only half the battle. Once your filter identifies a potential deepfake, the organization needs a clear protocol for what happens next. Simply cutting the call might alert the attacker too early. Some firms choose to insert a discreet watermark or warning for the host, allowing them to steer the conversation into a 'test' phase. This might involve asking the caller to turn their head quickly or hold up a specific object, actions that often break current real-time synthesis models.
Staying ahead of these threats requires constant iteration. As generative models improve, your detection models must be retrained on the latest synthetic datasets. This creates a cat-and-mouse game where the filter you build today might be obsolete in six months. By establishing a robust, modular pipeline now, you ensure that your enterprise can swap in new detection modules as they emerge, keeping your virtual boardroom secure against the next generation of AI-driven fraud.


