Why Local AI is the Standard in 2026
Running large language models on your own hardware used to be a hobby for enthusiasts. Today, it is a necessity for anyone serious about data privacy and latency. Cloud providers offer convenience, but they come with a hidden tax on your intellectual property and a reliance on their uptime. When you host locally, you own the weights, the logs, and the results. Recent shifts in the industry have made this easier than ever. According to a 2026 report by Gartner, over 45% of enterprise AI workloads have shifted to edge or local private clouds to mitigate data leakage risks.
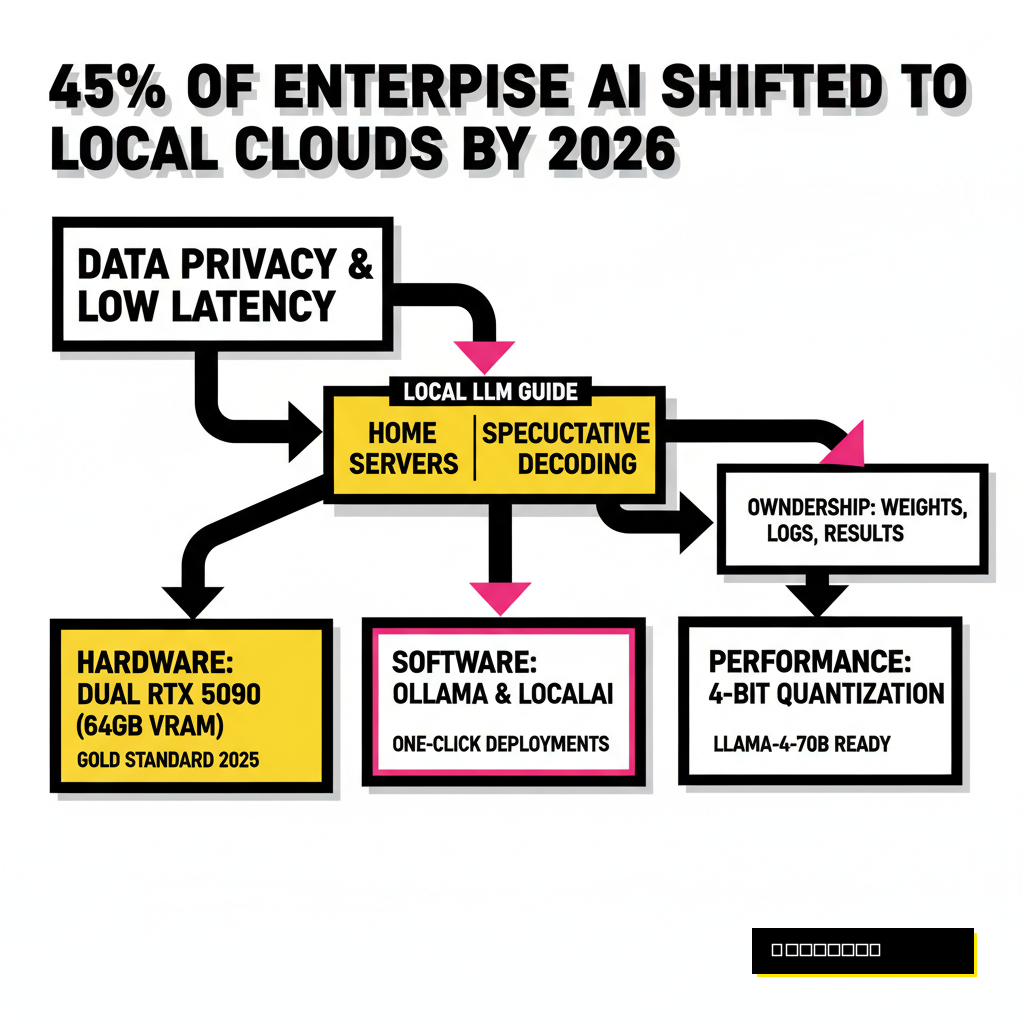
Building a home server requires a different mindset than building a gaming rig. You are not chasing frames per second. You are chasing VRAM capacity and memory bandwidth. A single NVIDIA RTX 5090, which became the gold standard for home labs in late 2025, provides 32GB of high-speed memory. This allows you to run models like Llama-4-70B at 4-bit quantization with respectable speeds. If you want to understand the basics of model compression, our Local LLM Handbook covers everything from GGUF to EXL2 formats.
Building the Foundation: Home Server Essentials
Choosing the right components for your server determines the ceiling of your AI capabilities. Most beginners make the mistake of overspending on the CPU while neglecting the GPU. In the world of local inference, the processor mainly handles data orchestration. The real work happens in the graphics card. For a balanced setup in 2026, I recommend a multi-GPU configuration. Two mid-range cards often provide more VRAM for the price than one flagship card, allowing you to load larger context windows without crashing.
The Starter Build
- NVIDIA RTX 5070 Ti (16GB VRAM)
- 64GB DDR5 System RAM
- 1TB NVMe Gen5 Storage
- 750W Gold Rated PSU
The Pro Build
- Dual NVIDIA RTX 5090 (64GB Total VRAM)
- 128GB DDR5 System RAM
- 4TB NVMe Gen5 Storage
- 1200W Platinum Rated PSU
Power delivery and cooling are your secondary concerns. Running a 70B parameter model at full tilt generates significant heat. Open-air frames or high-airflow cases like the Fractal Design Torrent are popular choices among the Proposia community. Ensure your power supply has the new 12VHPWR connectors to avoid using flimsy adapters that can melt under sustained loads. Reliability is more important than aesthetics when your server is running a 48-hour fine-tuning job.
Software Stacks and One-Click Deployments
Once the hardware is humming, you need a way to talk to it. The software landscape has matured significantly. Gone are the days of wrestling with broken Python dependencies and CUDA version mismatches. Tools like Ollama and LocalAI have turned complex deployments into single commands. These platforms provide an OpenAI-compatible API, meaning you can drop your local server into any existing application that supports GPT-4. This interoperability is crucial for maintaining 2026 AI compliance standards within your organization.
Performance tuning is the next hurdle. Most users simply load a model and hope for the best. Expert users optimize their context management. By using KV cache quantization, you can fit 2x more text into your memory without sacrificing much accuracy. This allows for deep document analysis that would otherwise be impossible on consumer hardware. We see many developers using these local setups to verify content, ensuring it meets the Verified Human SEO standards that search engines now demand.
The Expert Pivot: What is Speculative Decoding?
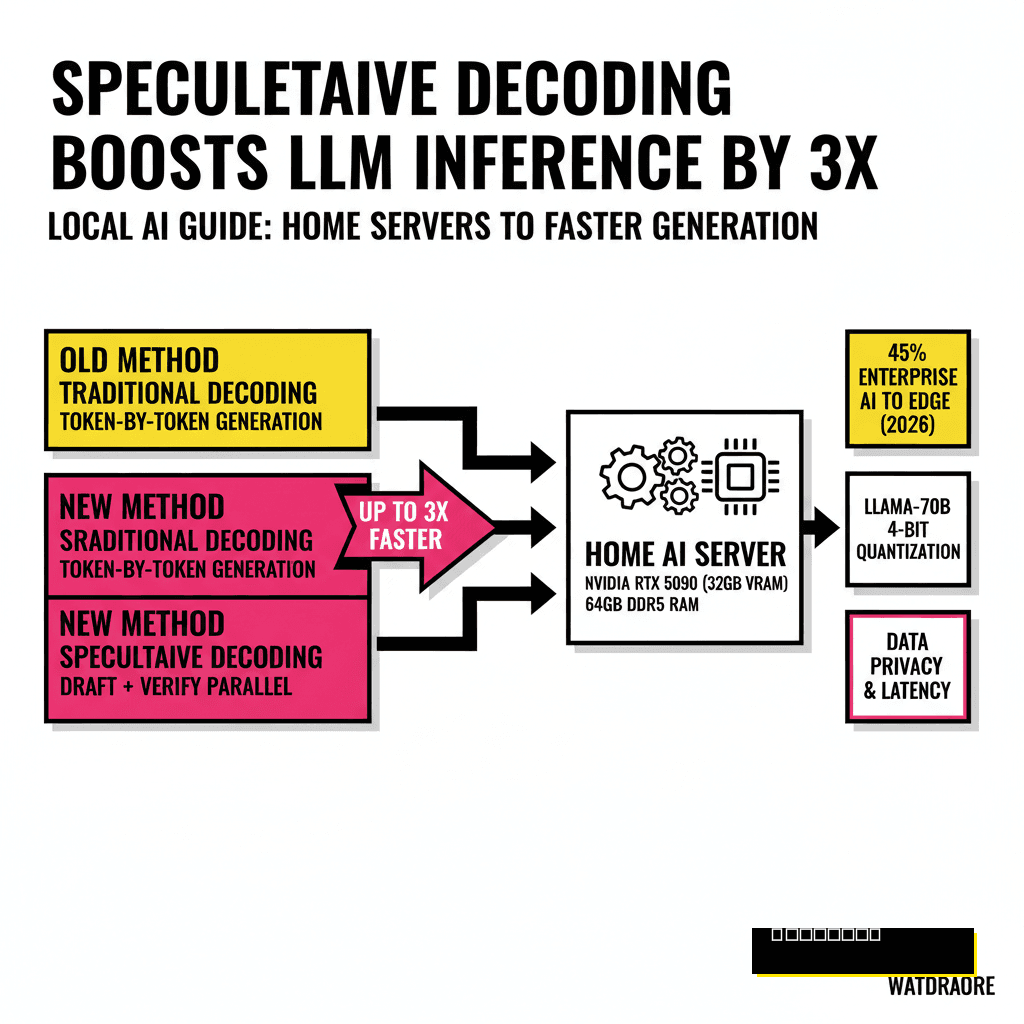
If you have mastered the basics, it is time to look at the cutting edge of inference speed. Speculative decoding is the most significant breakthrough in local AI efficiency this year. Standard inference is sequential. The model predicts one word at a time, which is slow because every word requires a full pass through a massive neural network. Speculative decoding changes the math. It uses a tiny, lightning-fast "draft" model to guess the next few words, then uses the large "target" model to verify them all at once.
Think of it like a senior editor and a junior writer. The junior writer drafts a sentence quickly. The senior editor looks at it and says, "Yes, those four words are correct, but change the fifth." Instead of the senior editor writing every single letter, they only have to make corrections. In technical terms, this leverages the parallel processing power of modern GPUs. According to research from arXiv, speculative decoding can improve tokens-per-second by up to 250% on consumer-grade hardware like the RTX 50-series.
Implementing Speculative Decoding at Home
Setting this up requires a bit more technical friction than a standard install. You need two models loaded into your VRAM simultaneously. Usually, you might pair a Llama-4-70B model with a Llama-4-1B draft model. Both models must share the same tokenizer to work effectively. Software frameworks like vLLM and TensorRT-LLM have started integrating this feature as a simple flag in their configuration files. It is the closest thing we have to a free lunch in the AI world.

The trade-off is memory. You need enough headroom to keep that second model in VRAM. This is why the Pro Build mentioned earlier is so valuable. With 64GB of VRAM, you can comfortably run a highly quantized 70B model alongside a 1B draft model and still have 20GB left for a massive context window. This setup allows you to process entire books or complex codebases in seconds. For those tracking market shifts, this level of local power is exactly what is needed to stay ahead of 2026 market volatility through real-time sentiment analysis.
Future-Proofing Your Local Lab
Technology moves fast, but the fundamentals of local LLMs are stabilizing. High VRAM, efficient quantization, and smart inference techniques like speculative decoding are the pillars of the modern home server. As we move deeper into 2026, the gap between cloud-based AI and local performance continues to shrink. By taking control of your hardware today, you are not just saving on API costs. You are building a private, secure, and incredibly fast intelligence engine that belongs entirely to you.
| Model Size | Min VRAM | Best Use Case |
|---|---|---|
| 8B Parameters | 8GB - 12GB | Chatbots, Simple Tasks |
| 30B Parameters | 24GB | Coding, Summarization |
| 70B+ Parameters | 48GB+ | Complex Reasoning, Creative Writing |
Start small if you must, but start now. The learning curve is steep, but the view from the top is worth it. Whether you are a developer looking for a local sandbox or a privacy-conscious professional, mastering these tools is the best investment you can make in the current era. Local LLMs are no longer just a trend. They are the backbone of a resilient digital strategy.

