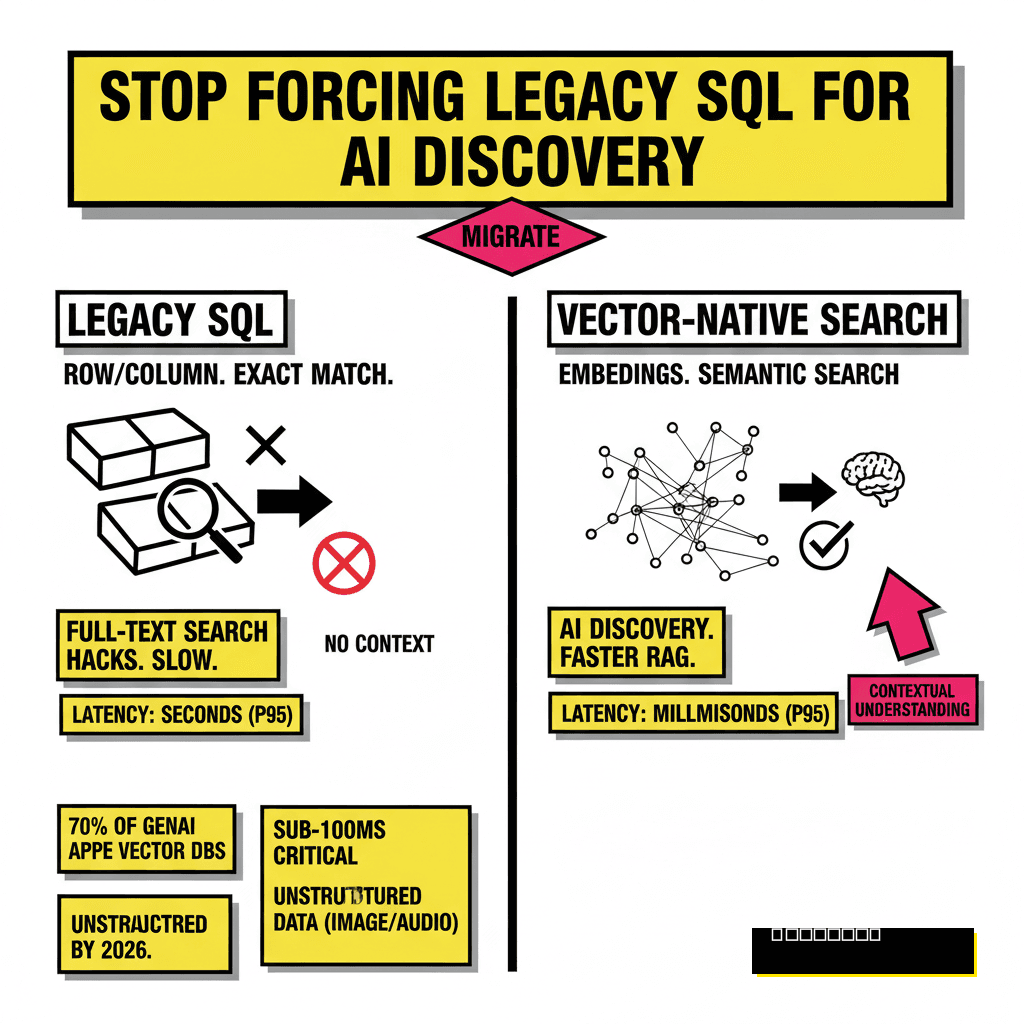
You have likely hit a wall with your current relational setup. For decades, SQL databases served as the gold standard for structured data. If you needed to find a user by ID or sum up last month's revenue, Postgres and MySQL were unbeatable. However, the rise of Retrieval-Augmented Generation (RAG) and agentic workflows has changed the requirements. Modern discovery requires understanding the intent behind a query rather than just matching keywords in a WHERE clause.
Moving from a legacy SQL database to a vector-native search engine is not a simple copy-paste operation. It involves a fundamental shift in how you represent and query information. Instead of rows and columns, you are dealing with high-dimensional embeddings that capture semantic meaning. I have seen teams spend months trying to hack full-text search into their existing relational tables, only to realize that the latency and recall simply cannot compete with purpose-built vector stores.
Breaking Free from Relational Constraints
Relational databases were designed for exactness. When a user searches for "comfortable running shoes," a standard SQL index looks for those specific characters. If your product description says "breathable athletic footwear," the database returns nothing. This rigid structure fails in an AI-first world where users expect systems to understand context.
Vector-native engines solve this by converting text into numerical arrays. These arrays, or embeddings, place similar concepts close together in a mathematical space. According to Ash Ashutosh, the CEO of Pinecone, vectors have become the new language of AI. They provide the memory and context that allow Large Language Models to function as knowledgeable machines rather than just intelligent predictors.
Building for the agentic future requires this transition. As we discussed in our guide on 9 agentic SEO tactics, discovery is no longer human-only. AI agents are now the primary navigators of data. If your backend cannot provide these agents with high-relevance context at sub-100ms speeds, your application will lag behind.
Quantifying the Vector Advantage
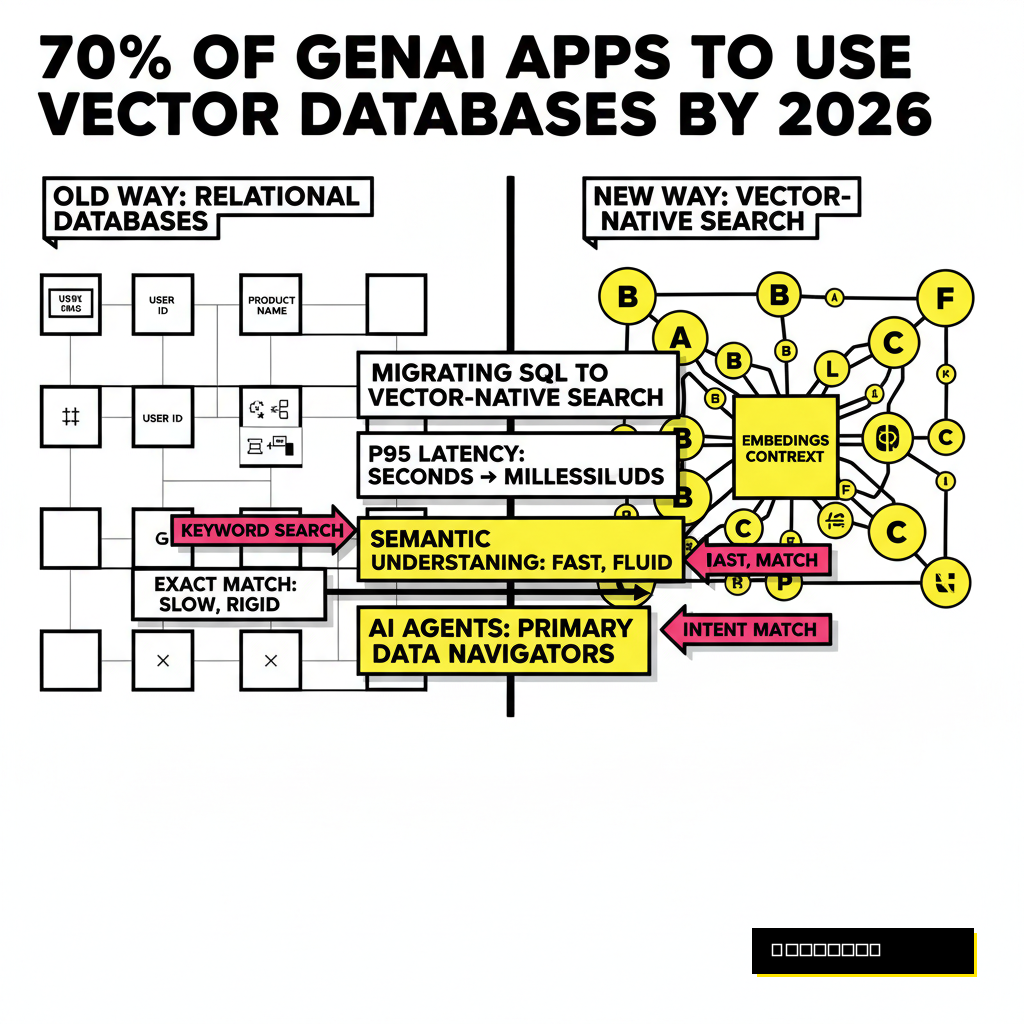
Switching architectures is a massive undertaking. You need hard data to justify the migration to stakeholders. Recent industry shifts suggest that vector databases are no longer a niche luxury. Gartner recently forecasted that by 2026, over 70% of generative AI applications will rely on vector databases. This move is driven by the need for speed and the increasing complexity of unstructured data like images and audio.
Performance benchmarks highlight the technical gap. While a standard PostgreSQL database using IVFFlat indexes might struggle as your dataset grows, specialized engines or newer extensions like pgvector with HNSW (Hierarchical Navigable Small World) indexes maintain high throughput. In many production environments, switching to a vector-native approach reduces p95 latency from seconds to milliseconds. This efficiency is critical when your system needs to handle the 2026 enterprise agentic battle for real-time responsiveness.
Efficiency matters, but cost often dictates the final choice. Reports from 2026 practitioners indicate that self-hosted Postgres solutions can cost 75% less than managed alternatives at scale. However, the operational overhead of managing your own sharding and indexing parameters often outweighs the monthly subscription for a managed service like Pinecone or Zilliz. You must weigh your team's DevOps capability against your growth projections.
The Migration Roadmap: From Rows to Embeddings
Starting the migration requires a clear pipeline. You cannot simply dump your SQL tables into a vector store. The process involves extraction, transformation through an embedding model, and finally, loading into the vector engine. Every step presents unique challenges, particularly around data consistency and chunking strategies.
Data freshness is usually the first hurdle. If your SQL database is still the primary source of truth for transactions, you need a way to sync updates to your vector store. Change Data Capture (CDC) tools are the standard here. These tools listen to your SQL transaction logs and trigger an embedding update whenever a row changes. Without this, your AI search results will eventually drift from reality, leading to halluncinations based on outdated data.
Transformation is where the heavy lifting happens. You must decide on an embedding model, such as OpenAI's text-embedding-3-small or a local HuggingFace model. The dimensionality of these vectors—often 1536 or 768—will determine your storage requirements. Larger vectors capture more nuance but increase latency and memory usage. Most developers find that 768 dimensions provide the best balance of performance and accuracy for enterprise search.
Choosing Your Vector Stack
Selecting the right destination for your data depends on your scale and existing infrastructure. The market in 2026 has bifurcated into two main categories: vector extensions for existing databases and purpose-built vector-native engines. If your team is already comfortable with PostgreSQL, pgvector is almost always the right starting point. It allows you to keep your relational data and vectors in the same ACID-compliant environment.
Specialized engines like Pinecone or Milvus become necessary when you scale past 50 million vectors. These systems are engineered for distributed workloads and provide features like automatic sharding and advanced metadata filtering that SQL extensions sometimes lack. For example, Milvus is widely regarded as the powerhouse for billion-scale deployments, while Pinecone remains the leader for teams prioritizing a zero-ops experience.
| Engine | Best For | Latency (p50) | Operational Effort |
|---|---|---|---|
| pgvector | Small-Medium Teams | ~18ms | Low (Postgres) |
| Pinecone | Managed Cloud | ~8ms | Minimal |
| Milvus | Billion-Scale OSS | ~6ms | High |
| Qdrant | High-Performance OSS | ~4ms | Medium |
Latency numbers often tie-break between two similar options. Qdrant has consistently led open-source benchmarks due to its Rust-based architecture, offering p50 latencies as low as 4ms. However, if your application requires complex joins between metadata and vectors, the overhead of moving data between a separate vector store and your SQL database might negate those speed gains. In such cases, the unified approach of pgvector or MongoDB Atlas Vector Search often wins.
Implementing the Chunking Strategy
Relational rows are often too long to embed effectively. An entire blog post or a massive product manual contains too many disparate concepts for a single vector to represent. You must break your data into smaller chunks before embedding. This is where most developers make their first big mistake: choosing a chunk size that is either too small to be meaningful or too large to be specific.
Fixed-size chunking is the easiest to implement. You simply cut the text every 500 characters. While this is fast, it often cuts off sentences mid-thought, destroying the semantic context. Semantic chunking is the superior, albeit more complex, alternative. It uses natural language processing to identify boundaries like paragraphs or topic shifts, ensuring each chunk contains a coherent idea.
Fixed-Size Chunking
- Fastest implementation speed
- Uniform vector storage requirements
- High risk of context loss
- Poor performance for long-form content
Semantic Chunking
- Preserves logical context
- Significantly higher retrieval accuracy
- Requires more initial compute
- Varying chunk sizes complicate batching
Overlap is your safety net. Regardless of the chunking method, you should always include a small amount of text from the previous chunk. This prevents the loss of context at the boundaries. A 10% to 20% overlap is generally sufficient to ensure that the embedding model captures the relationship between adjacent segments.
Managing the Production Pipeline
Once your migration is live, the focus shifts to optimization. You cannot just set it and forget it. Vector search quality is measured by recall—the percentage of relevant results actually retrieved. If your recall is low, you may need to adjust your distance metrics. Most text-based RAG systems use Cosine Similarity, but Dot Product can be faster if your vectors are already normalized.
Monitoring for "vector drift" is also essential. As your data evolves, the original embedding model might become less effective at representing new concepts. Periodically evaluating your embeddings against a golden dataset of known high-quality results will help you decide when it is time to re-index. This is particularly important for industries with rapidly changing terminology, such as tech or finance.

Successful migration is about more than just technology. It is about enabling a new kind of user experience where information finds the user, rather than the other way around. By moving your legacy SQL data into a vector-native environment, you are building the foundation for the next generation of AI-first discovery. Start small, focus on data quality, and let the semantic proximity do the heavy lifting.

