1. Introduction: The Silent Revolution in Your Pocket
While the tech world remains fixated on the "loud" hype of massive, power-hungry cloud data centers, a quieter and far more consequential revolution is unfolding inches from your palm. The era of the monolithic, distant cloud is being challenged by a "Pocket Data Center" philosophy. We are moving past the days when a smartphone was merely a window into a remote supercomputer; today, through breakthroughs in silicon and software architecture, the intelligence lives directly on the glass.
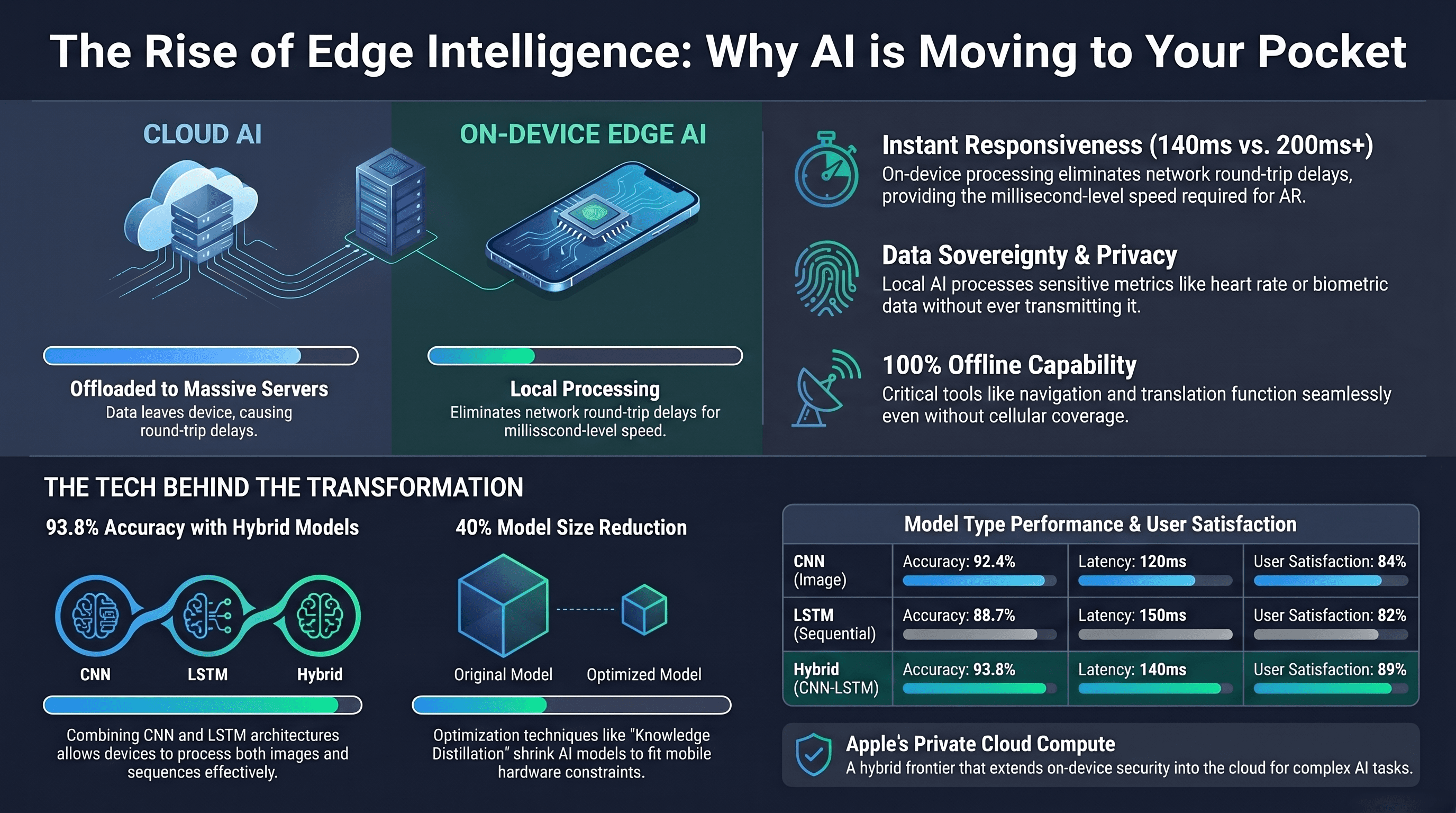
The goal is no longer just how massive an AI can be, but how small it can become without losing its "soul." This shift to on-device and edge AI is driven by a fundamental technical realization: local intelligence is the only way to achieve the trifecta of millisecond speed, uncompromising privacy, and absolute reliability. By distilling the power of a 3-billion parameter model into a form factor that fits in your pocket, we are witnessing a structural shift that redefines our relationship with technology.
2. The Power of "Two-in-One": Why Hybrid Models Are Winning
At the heart of this revolution is a new kind of "super-brain" recently highlighted in the World Journal of Advanced Research and Reviews: the Hybrid CNN-LSTM model. To understand its impact, imagine the difference between a system that can see a frame and one that can understand a story. Convolutional Neural Networks (CNNs) are world-class at image processing, while Long Short-Term Memory (LSTM) networks excel at identifying sequential patterns over time.
By fusing these architectures, mobile devices can now "see" and "remember" context simultaneously. This isn't just an academic exercise; the hybrid model achieves a staggering 93.8% accuracy and 92.1% precision. Crucially, this high-performance threshold is what makes the "privacy-first" model viable. If on-device models weren't this accurate, users would be forced to send their data back to the cloud for more reliable processing. Now, your device can handle complex tasks like advanced augmented reality or real-time healthcare monitoring locally, with a manageable latency of just 140 ms.
"The Hybrid CNN-LSTM model achieves superior accuracy (93.8%), precision (92.1%), and F1-score (91.5%) compared to standalone CNN or LSTM models... making it optimal for tasks requiring both image and sequential data processing." — World Journal of Advanced Research and Reviews
3. The "Shrink Ray": Defying the Physics of Silicon
How do you fit a data-center-grade intelligence into a device limited by battery and thermal constraints? The answer lies in optimization techniques that feel like technical "shrink rays." We are currently seeing the frontier of this with 2-bit quantization-aware training and KV-cache sharing, innovations that allow models to retain their "IQ" while shedding massive amounts of weight.
The primary pillars of this efficiency are not just lines on a datasheet; they are the difference between a useful tool and a dead battery:
Knowledge Distillation: This is the gold standard of compression. By training a smaller "student" model to mimic a massive "teacher" model, engineers can achieve a 40% size reduction and 25% faster response times. Its meager 10mAh battery draw is, quite literally, the difference between your phone dying during dinner or lasting through a late-night commute.
Quantization: By converting high-precision data into lower-bit integers—pushing now into the extreme 2-bit frontier—we can slash memory footprints to 150MB and reduce latency by 20%. It turns complex calculations into a shorthand the processor can finish in its sleep.
Pruning: This involves surgically removing the redundant connections within a neural network. It shrinks the model by 28%, ensuring that every milliwatt of power is spent on meaningful computation rather than idling through "dark" neurons.
4. Privacy as a Technical Guarantee: The "Private Cloud" Paradox
As AI becomes more personal, privacy can no longer be a marketing promise; it must be a technical guarantee. This is the "Private Cloud" paradox: the ability to use cloud-scale power without the cloud-scale risk. Apple’s Private Cloud Compute (PCC) architecture solves this by extending the security of your iPhone directly into the data center using custom Apple silicon and a novel Parallel-Track Mixture-of-Experts (PT-MoE) transformer.
PCC is built on five non-negotiable requirements: stateless computation (data leaves no trace), enforceable guarantees, no privileged access (not even Apple can peek), non-targetability (attackers can't pick a victim), and verifiable transparency. This last feature is the "luxury" of modern AI: Apple releases software images of every production build for independent researchers to inspect. If the software isn't public, your device simply refuses to send the data.
"Private Cloud Compute extends the industry-leading security and privacy of Apple devices into the cloud, making sure that personal user data sent to PCC isn't accessible to anyone other than the user — not even to Apple." — Apple Security Research
5. Latency Logic: From 500ms to the Speed of Thought
In the realm of mission-critical AI—think autonomous navigation or cardiac monitoring—latency isn't just a metric; it’s a safety requirement. Traditional cloud AI suffers from round-trip delays of 500ms or more. According to the International Research Journal of Engineering and Technology (IRJET), moving to Edge AI can slash this by 90%, dropping delays to under 50ms.
This is made possible by Multi-access Edge Computing (MEC), which brings the computational powerhouse to the base station nearest you. By eliminating the long trek to a distant server, we transition from "waiting for a response" to the speed of thought.
6. The "Invisible" AI: Why the Best Interface is None at All
This low latency is precisely what makes AI "invisible." If there is a lag, the AI is a visible, annoying gimmick. But when the hybrid brain in your pocket reacts instantly, the technology disappears. We see this in "Subtle AI" features: Siri providing contextual suggestions before you ask, Photos auto-sorting thousands of images, or Mail drafting responses that match your unique tone.
This seamless integration is a brilliant business moat. Moving AI to the device eliminates massive server and electricity overheads while making the physical hardware exponentially more valuable. The strategy is working: the World Journal notes that 89% of users report high satisfaction with these models. Crucially, this satisfaction isn't just about the features—it is a direct result of the raw performance and responsiveness of the hybrid on-device brain.
7. Conclusion: The Future is Personal, Not Centralized
The narrative of AI is pivoting away from monolithic, centralized clouds toward a distributed, highly optimized network of intelligence that lives where we do. Through hybrid architectures and radical optimization, our devices have become more than just portals; they are personal, private, and incredibly powerful assistants that don't need a constant tether to be smart.
As this technology continues to evolve, we must ask ourselves: In a world where intelligence is everywhere, who do you trust more—a distant, opaque server, or the device you hold in your hand?

