The Economics of High-Dimensional Retrieval
Scaling a Retrieval-Augmented Generation (RAG) system from a prototype to a production-grade index of 10 million documents is the moment most engineering teams hit a financial wall. What worked for a few thousand vectors suddenly becomes a source of significant cloud spend. At this scale, the choice between Pinecone Serverless and Weaviate is no longer about which API is easier to use. It is about the fundamental architecture of how data is stored, indexed, and queried. If you are building a system that needs to retrieve context for LLMs across millions of records, you are likely feeling the pressure of balancing sub-100ms latency with a monthly bill that does not consume your entire infrastructure budget.

Engineers often underestimate the storage overhead of high-dimensional vectors. A standard 1536-dimension embedding from an OpenAI model takes up significant space, and when you multiply that by 10 million, you are looking at roughly 60GB to 90GB of raw data before accounting for indexing structures like HNSW. As Edo Liberty, the founder of Pinecone, mentioned in a 2025 interview, trying to replicate high-performance computing at this scale without a specialized architecture is often nauseatingly expensive. You are not just paying for the disk space; you are paying for the memory and compute required to navigate that space in milliseconds.
Pinecone Serverless: Decoupled Storage and Compute
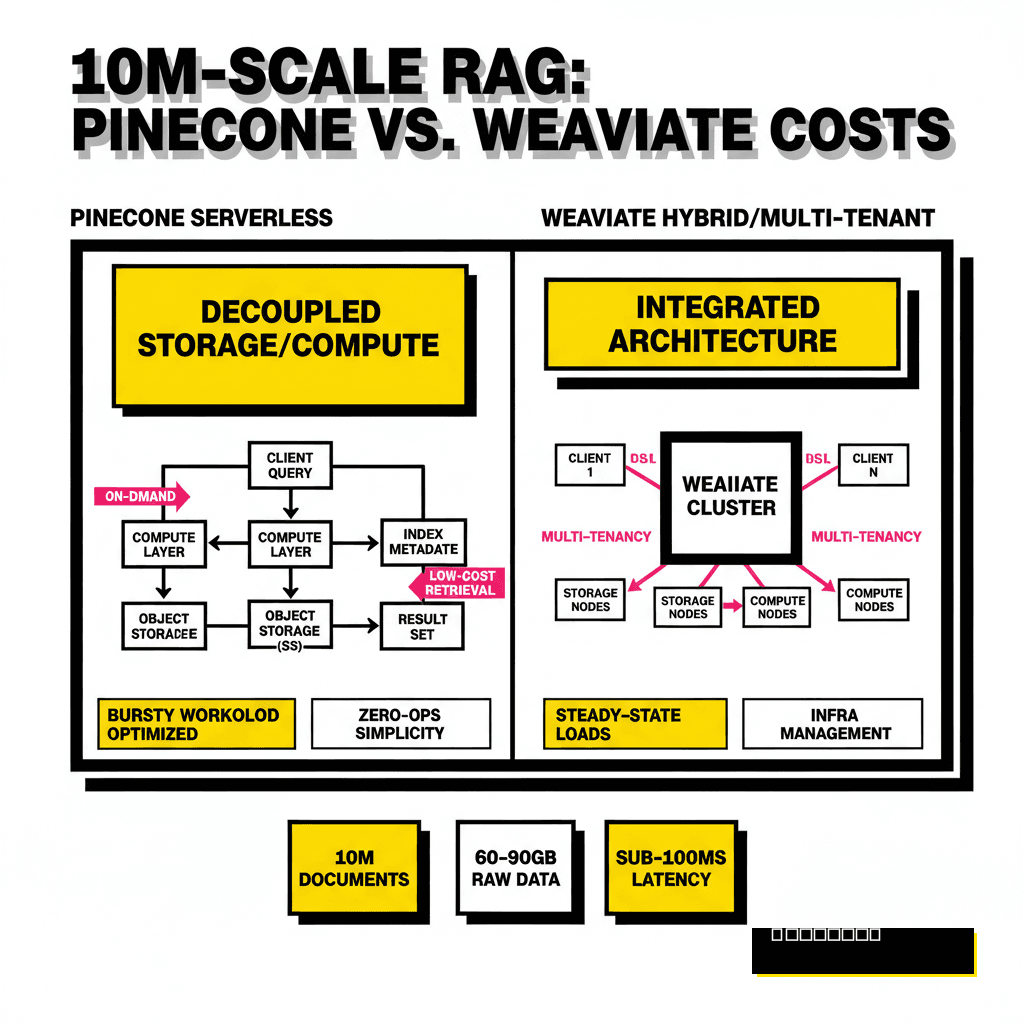
Pinecone Serverless represents a departure from the traditional pod-based model where you pay for reserved capacity regardless of usage. The core innovation here is the decoupling of storage from compute. Your vectors live in low-cost blob storage like AWS S3, and Pinecone spins up compute resources on demand to perform searches. This architecture is particularly effective for bursty workloads where query volume varies throughout the day. You avoid the idle cost of keeping a massive HNSW index loaded in RAM 24/7, which was the primary cost driver in older vector database versions.
Operational simplicity is the biggest draw for Pinecone. You do not have to manage sharding, replication, or index tuning. However, this zero-ops experience comes with a price tag that scales with your activity. According to 2026 pricing data, Pinecone charges approximately $0.33 per GB per month for storage and bills for Read Units (RUs) and Write Units (WUs). For a 10 million document index, your storage costs are negligible, but your query costs can spike if you have high traffic. If you are looking to integrate these databases with edge-case models, check out our guide on 6 lightweight LLMs you can run locally for faster iteration during the development phase.
Weaviate: The Hybrid Search and Multi-Tenancy Choice
Weaviate offers a different value proposition by providing both a managed cloud service and a fully open-source version. For developers who need precise control over their data or have strict regulatory requirements, Weaviate's self-hosting option is a massive advantage. At the 10 million document mark, Weaviate's native multi-tenancy shines. It allows you to isolate data for thousands of different users within a single cluster without the performance degradation often seen in namespace-based systems. This makes it a preferred choice for B2B SaaS platforms where data isolation is a core requirement.
Pinecone Serverless
- Zero operational overhead
- Pay-as-you-go usage model
- Best for bursty query patterns
- Proprietary, closed-source
Weaviate Cloud
- Open-source flexibility
- Native hybrid search (BM25)
- Strong multi-tenant isolation
- Predictable dimension-based billing
Hybrid search is another area where Weaviate maintains a lead. It combines keyword-based BM25 search with vector similarity in a single query, which is vital for RAG applications that need to find specific product IDs or unique names that embeddings might miss. While Pinecone has introduced metadata filtering, Weaviate's implementation of hybrid search is more mature and easier to tune. This becomes increasingly important as you build complex agents, such as those discussed in our article on building multimodal AI safety agents, where retrieval needs to be precise and context-aware.
Calculating the Real Bill: 10 Million Vectors in Production
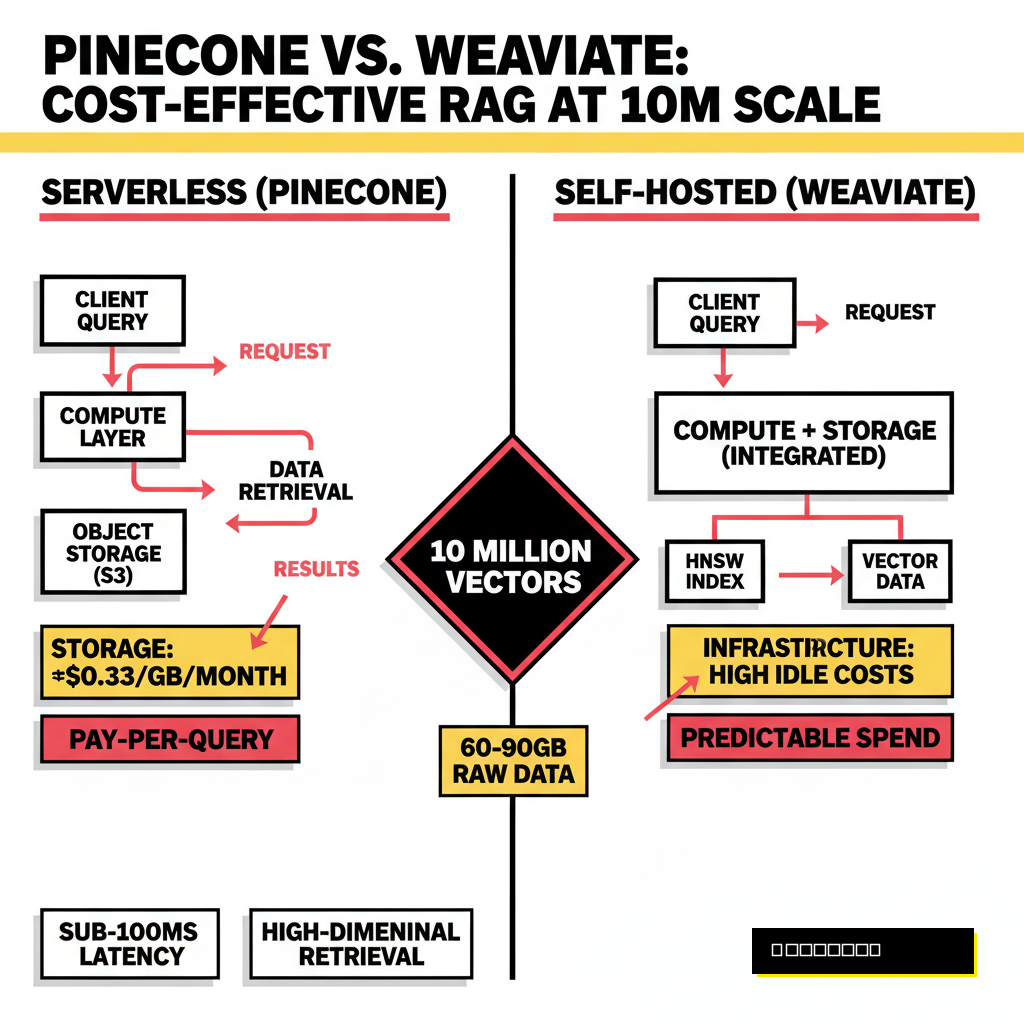
Are you actually saving money by going serverless? The answer depends entirely on your Query-to-Ingestion Ratio (QIR). In 2026, Pinecone Serverless pricing is driven by read units, costing roughly $16 per million RUs on the Standard plan. A typical query on a 10 million vector index might consume multiple RUs depending on the metadata filters applied. In contrast, Weaviate Cloud Flex pricing uses a dimension-based model, charging $0.01668 per million vector dimensions per month. For a 10M index with 1536 dimensions, the base cost for dimensions alone is around $256 per month, plus storage fees of $0.255 per GiB.
| Metric (10M Vectors) | Pinecone Serverless | Weaviate Cloud (Flex) |
|---|---|---|
| Storage Cost (per GB) | $0.33 / month | $0.255 / month |
| Base Dimension Fee | $0.00 | ~$256.20 / month |
| Query Cost (per 1M) | $16.00 (Standard RU) | Usage-based (Variable) |
| Est. Total (Low Traffic) | $70 - $100 / month | $280 - $320 / month |
Data from recent production case studies suggests that Pinecone is the clear winner for low-traffic applications or internal tools where the index is large but queries are infrequent. However, as your query volume passes the 60 million per month threshold, the usage-based read units in Pinecone can quickly exceed the cost of a managed Weaviate cluster or a self-hosted instance. A team at a mid-sized fintech firm reported that migrating to self-hosted Weaviate on AWS r6g instances saved them over $2,000 per month once their agentic workflows reached 100 million queries monthly. This tipping point is critical for long-term financial planning.
Performance and Latency Trade-offs
Latency is the silent killer of user experience in AI applications. When you query a 10 million document index, every millisecond of overhead in the retrieval step adds to the total time-to-first-token for your LLM response. In independent 2026 benchmarks, Weaviate Cloud demonstrated impressive tail latency, with P99 scores around 6.1ms for HNSW-indexed data. Pinecone Serverless, while highly optimized, showed slightly higher tail latency at approximately 33ms for dense 10M vector workloads. This difference is often due to the architectural need for Pinecone to fetch data from object storage if it is not already cached in the compute layer.
Recall is another factor that developers tend to overlook until they notice their RAG system is missing obvious answers. Both databases perform exceptionally well here, with Weaviate hitting 97.2% and Pinecone at 96.5% in standardized benchmarks. The choice often comes down to how much you need to tune the index. Weaviate allows for extensive configuration of HNSW parameters like efConstruction and maxConnections, whereas Pinecone abstracts these away. If you need consistent sub-10ms performance and have the engineering bandwidth to tune your index, Weaviate provides the necessary knobs to turn.
The Verdict: Choosing Your Vector Stack
Choosing between these two powerhouses requires an honest assessment of your team's operational capacity and your application's traffic patterns. If you are a startup or a small team that needs to ship a RAG application yesterday, Pinecone Serverless is the most logical choice. It removes the burden of infrastructure management and offers a low entry cost that is hard to beat for prototypes and low-traffic products. You can focus on your prompt engineering and agent logic without worrying about Kubernetes clusters or memory limits. The cost of Pinecone only becomes a concern once you achieve significant scale, at which point you likely have the resources to consider a migration.
Weaviate is the superior choice for enterprise-grade applications where data sovereignty, hybrid search, and multi-tenancy are non-negotiable. Its ability to be self-hosted means you can run it inside your own VPC, keeping sensitive customer data within your security perimeter. For high-throughput applications processing tens of millions of queries, the predictable cost of self-hosted infrastructure will consistently outperform the usage-based billing of a serverless model. Decisions made at the 10 million document mark will define your product's margins and performance for years to come, so choose the stack that aligns with your long-term growth strategy rather than just your immediate needs.

