
The End of Frankenstein RAG
Building a production-ready AI assistant used to feel like an exercise in assembling a digital Frankenstein. Developers spent 2024 and 2025 stitching together frozen language models, disparate vector databases, and brittle embedding pipelines. Douwe Kiela, CEO of Contextual AI, famously labeled this the Frankenstein approach because these components were never actually designed to work in harmony. You likely remember the frustration of watching a model hallucinate simply because the retriever pulled in three irrelevant paragraphs while missing the one critical sentence buried in a table. Standard vector retrieval relies on semantic similarity, which is essentially a high-dimensional vibe check. It works for finding concepts, but it fails miserably when you need precise, relational facts across multiple documents.
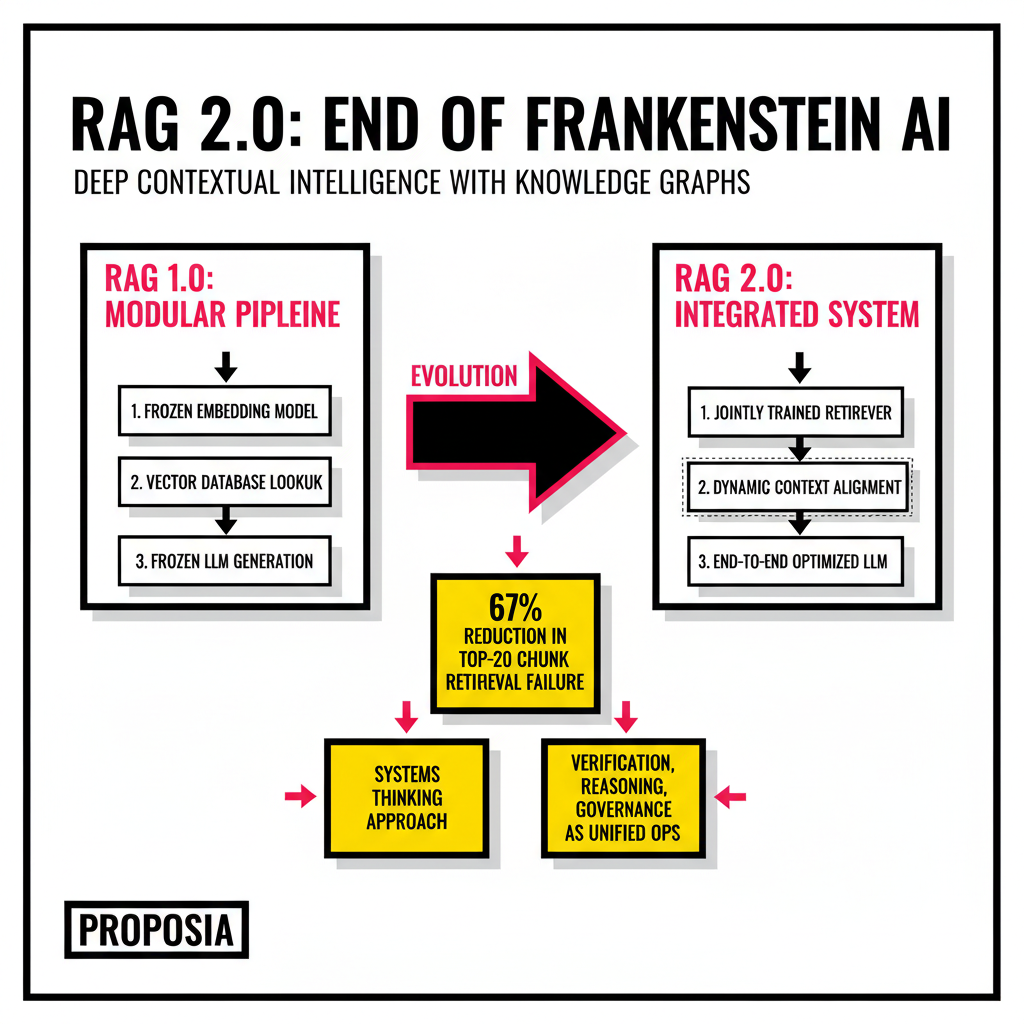
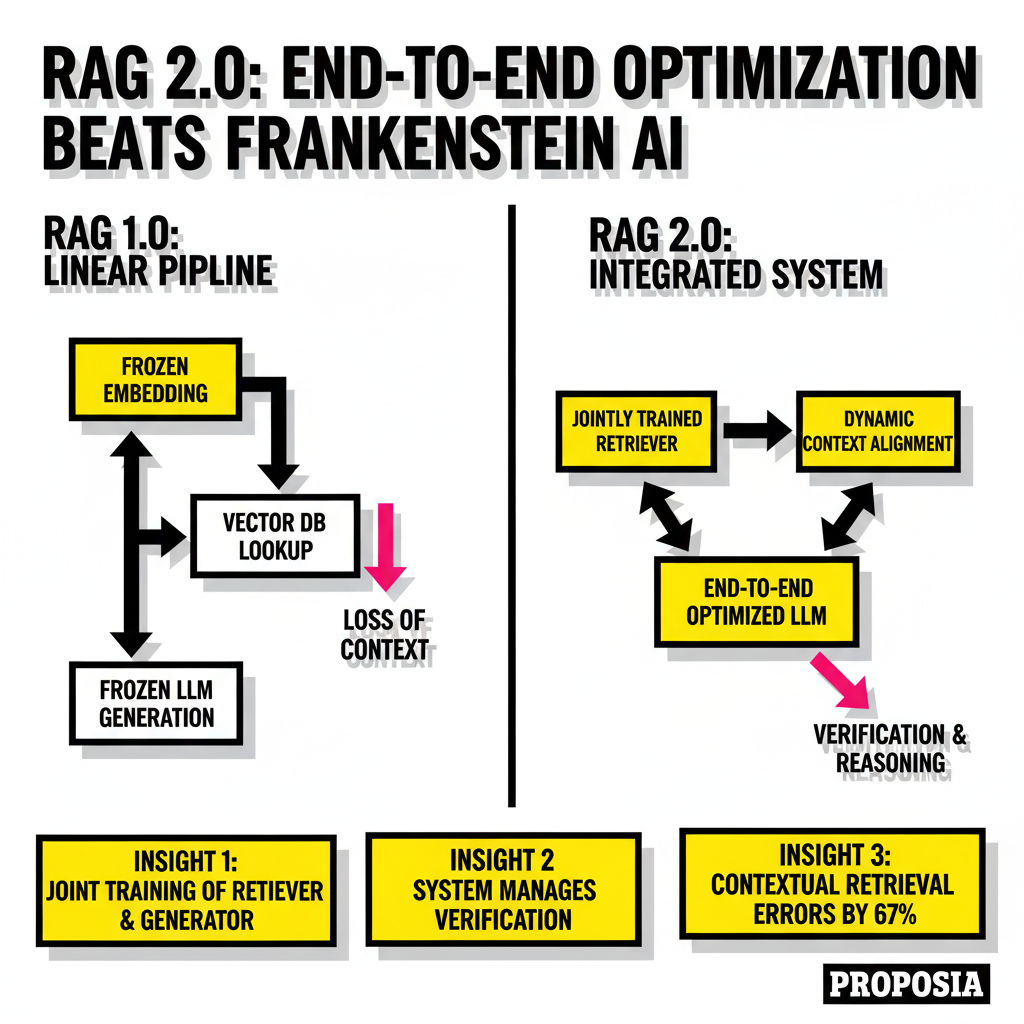
Recent shifts in the industry have moved us toward what we now call RAG 2.0. This new paradigm treats the entire stack as a single, end-to-end optimized system. Instead of using off-the-shelf models in a linear sequence, RAG 2.0 involves joint training of the retriever and the generator. When these components learn together, the retriever becomes specialized for the specific knowledge base it serves. This transition is less about the model size and more about the architectural synergy. If your retrieval step is lossy, your generation step will be flawed, regardless of how many billions of parameters your LLM possesses.
Defining RAG 2.0: The Systems Shift
Why did your production RAG system fail even with a top-tier LLM? The answer usually lies in the disconnect between how models process information and how data is stored. RAG 1.0 was a pipeline, but RAG 2.0 is a runtime. This means the system doesn't just fetch and stuff context into a prompt. It manages verification, reasoning, and governance as unified operations. This systems thinking approach has been proven in other domains like speech recognition, where end-to-end optimization dramatically outperforms modular systems. According to Contextual AI research, these integrated models achieve state-of-the-art performance by backpropagating through both the language model and the retriever simultaneously.
Developers are also seeing massive gains from Anthropic's Contextual Retrieval technique. By prepending every text chunk with a brief explanatory context before embedding it, the top-20 chunk retrieval failure rate drops by 67 percent. This simple preprocessing step ensures that a sentence like The company revenue grew by 3 percent is no longer an isolated data point. It becomes This chunk is from the Q3 2025 report for ACME Corp, followed by the original text. This method bridges the gap between semantic search and precise fact retrieval without requiring a total overhaul of your existing vector store.
Knowledge Graphs: The Multi-Hop Solution
Vector search is excellent at finding things that look like your query, but it is blind to how those things relate to one another. If you ask a system to find the revenue growth of a company whose CEO attended Stanford, a vector search might find documents about the CEO and documents about the revenue, but it often fails to connect the two. Knowledge Graphs (KGs) solve this by representing data as nodes and edges. Entities like People, Companies, and Events are nodes, while relationships like EmployedBy or FoundedIn are the edges that connect them. This structure allows the AI to perform multi-hop reasoning, traversing the graph to find answers that require synthesizing facts from multiple disparate sources.
Microsoft Research introduced GraphRAG in 2024 to address exactly this. By using an LLM to build a hierarchical knowledge graph from unstructured text, the system can perform global summarization. It doesn't just answer what is in this document; it answers what are the major themes across 10,000 documents. The Leiden algorithm helps cluster these entities into thematic communities, which the LLM then summarizes. This process creates a map of your data that the retriever can navigate with far more intent than a simple similarity search. For those building complex internal tools, checking out the Devin vs. Cursor comparison reveals how critical context becomes when AI agents start managing entire codebases.
GraphRAG vs Vector Search: Benchmarking Intelligence
The performance delta between graph-based and vector-only systems is no longer a matter of debate. In enterprise scenarios involving KPIs and forecasts, traditional vector RAG often plateaus. A 2025 benchmark by FalkorDB showed that vector RAG scored effectively 0 percent on schema-bound queries that required complex aggregations. In contrast, GraphRAG implementations achieved over 90 percent accuracy. This is because graphs preserve the structural fidelity of the data, whereas vectors compress it into a lossy semantic space. When precision matters, the graph is a structural requirement, not an optional feature.
Microsoft's internal testing further supports these findings. Their research indicated that GraphRAG achieved 80 percent correct answers compared to 50.83 percent with traditional RAG. When dealing with complex technical specifications in the industrial sector, the gap was even wider, with GraphRAG providing 90.63 percent correct answers. These figures highlight why major cloud providers are integrating graph capabilities directly into their AI stacks. For instance, Amazon Bedrock now offers managed GraphRAG support via Amazon Neptune, allowing developers to combine relational depth with generative power without managing the underlying infrastructure.
Practical Implementation for 2026
Starting with a hybrid approach is usually the most pragmatic move for most development teams. You don't necessarily need to replace your vector database; you need to augment it. Modern frameworks like LlamaIndex and LangGraph allow you to route queries based on their complexity. Simple factual lookups can still go to your vector store for speed and cost-efficiency. Complex, multi-step queries that require reasoning across document boundaries should be routed to a graph-traversal layer. This hybrid strategy balances the low latency of vector search with the high precision of knowledge graphs.
| Feature | Vector RAG (1.0) | GraphRAG (2.0) |
|---|---|---|
| Data Representation | Unstructured text chunks | Entities and relationships |
| Reasoning Depth | Single-point similarity | Multi-hop traversal |
| Scalability | High (millions of vectors) | Medium (complex traversal) |
| Explainability | Opaque (distance metrics) | Transparent (path provenance) |
Tool selection has also matured significantly. LlamaIndex remains the retrieval specialist for document-heavy enterprise knowledge bases, offering a 35 percent boost in retrieval accuracy in recent benchmarks. LangChain, through its LangGraph extension, provides the stateful orchestration needed for agentic workflows. When you're building a system that needs to think, plan, and revise, LangGraph is the current gold standard. For the storage layer, Neo4j and FalkorDB have emerged as the leaders in graph-native RAG, providing the indexing speed required to keep query latencies in the 100ms range. As we see more Gen Alpha users ditching the search bar for voice AI, the demand for this kind of instant, accurate reasoning will only increase.
Contextual Intelligence as the New Baseline
The transition to RAG 2.0 and Knowledge Graphs represents a fundamental shift in how we treat data for AI. We are moving away from treating information as a pile of strings to be searched and toward treating it as a network of knowledge to be understood. This shift is driven by the economic imperative to ground AI systems in verifiable truth rather than probabilistic guesses. For developers, this means the retrieval pipeline is now the most critical part of the stack. If your retriever fetches the wrong evidence, no amount of prompt engineering or model scaling will save the output. Deep contextual intelligence is no longer a luxury for specialized research; it is the new baseline for any production AI system that aims to be more than a demo.
Sourcing Log
- Statistic: GraphRAG achieved 80% correct answers compared to 50.83% with traditional RAG. - AWS Machine Learning Blog
- Statistic: Contextual Retrieval reduced the top-20-chunk retrieval failure rate by 67% (5.7% to 1.9%). - Anthropic Official Documentation
- Statistic: Vector RAG scored 0% on schema-bound queries like KPIs and forecasts, while GraphRAG reached 90%+ accuracy. - FalkorDB Accuracy Benchmark
- Quote: "RAG 2.0 is about making sure that all of the components of a modern RAG pipeline... are designed to work well together." - Douwe Kiela, CEO of Contextual AI, June 2025.
- External Link: Microsoft Research on GraphRAG. - Microsoft Research
- External Link: Neo4j GraphRAG Implementation Guide. - Neo4j Developer Blog

